はじめに
以前、以下の記事で、ローカルLLMを用いた、レシピ検索アプリの構築を試してみました。

このアプリに関して、きちんとClean Archetectureで構築しようとしたのが今回の記事で書くことになります。
Clean Archetectureとは
Clean Archetectureとは2012年にロバート・C・マーティン氏によって提唱されたアーキテクチャの概要で、アーキテクチャ設計をする上でのルールのようなものです。
そのルールは、依存の向きをビジネスロジックに向けるということです。
以下の図がClean Archetectureの概念図です。
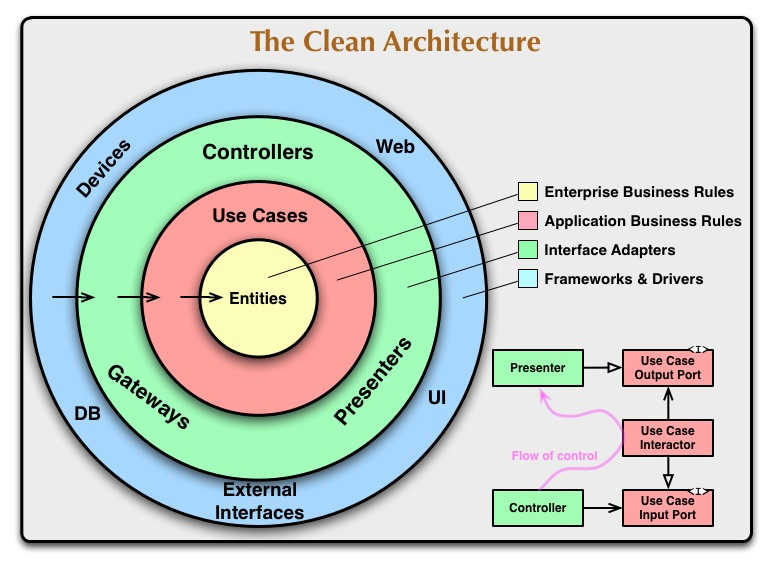
引用元:「クリーンアーキテクチャ(The Clean Architecture翻訳)」(https://blog.tai2.net/the_clean_architecture.html )
細かな内容に関しては以下のサイトでとてもよくまとめられていました。
図にある4色のレイヤーごとに関心事を分離し、依存の向きを適切に制御することになります。
frontendとbackendの構成
frontend
froentendはかなり簡単な作りになっています。
白の四角がclassを表しており、classからclassへの太い矢印が依存関係を示しています。
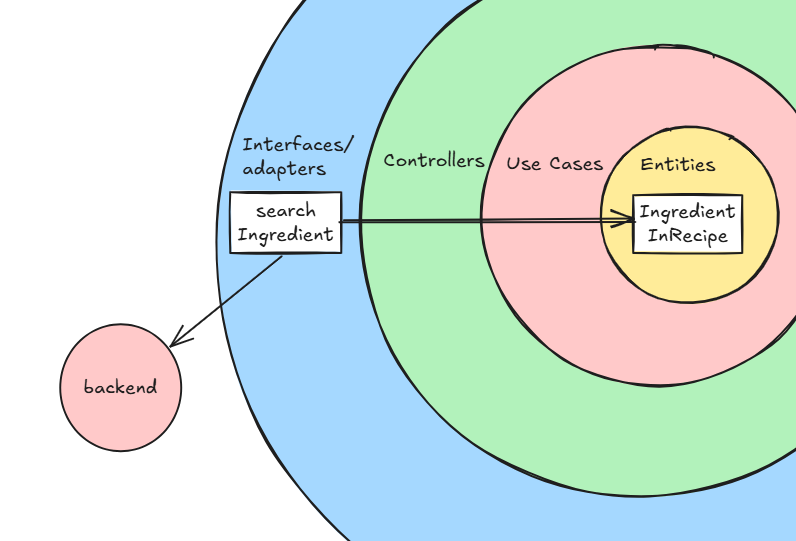
つまり、この図からはsearchIngredientはIngredientInRecipeというクラスに依存しています。(Lower キャメルと Upperキャメルが混合しているところはここではご愛嬌ということで。)
そしてsearchIngredientというclassはbackendへアクセスを行います。
以下のようなになります。
export async function searchIngredient(
serch_ingredient: string,
): Promise<IngredientInRecipe[]> {
const res = await axios.get("http://localhost:3000/recipes/search", {
params: { query: serch_ingredient },
});
console.log(res);
return res.data;
}ここからbackendへデータが送られて、次はbackendで処理が行われます。
backend
backendはbackendでまたClean Architectureの形をとります。
backendをClean Architectureの図に落とし込むと以下のような図になっています。
オレンジの矢印が依存関係を示しています。
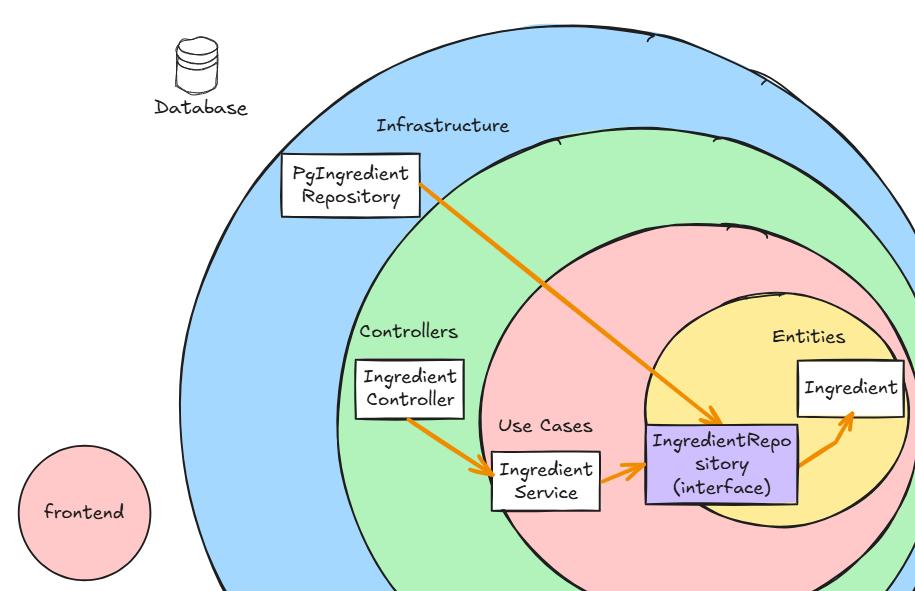
依存関係(オレンジの矢印)が中心に向かってすべて向いていることが分かります。
これにより、Infrastructure層の変更をした際に、Entities層のclassを変更する必要がなくなります。
紫の四角はinterfaceを表しており、これがある事で、中心に向かって依存関係ができるようになります。(これが所謂、依存性の注入です。)
データの流れを表したものが以下の図になります。
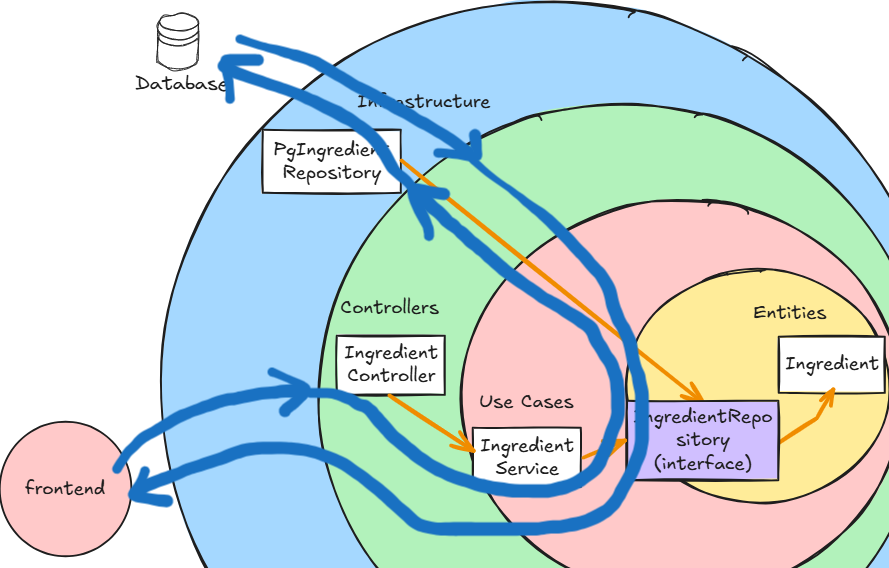
コードに関して一部抜粋しながら見ていこうと思います。
Controllers層では、frontendとのデータのやり取りを行っています。
Infrasctructure層(フレームワークドライバー)とUseCase層とのやり取りの緩衝材の役割を持つので、Use Caseで扱いやすいデータ構造に変換したりします。
import { Controller, Get, Query, Post, Body } from '@nestjs/common';
import { IngredientService, RecipeService } from "../usecase/recipe.service";
@Controller('ingredient')
export class IngredientController {
constructor(private readonly ingredientService: IngredientService) { }
@Get('search')
async search(@Query('query') query: string) {
console.log(query)
try {
const results = await this.ingredientService.searchIngredientByQuery(query);
return results;
} catch (err) {
console.error(err);
throw new Error('検索失敗');
}
}
}Usecases層では、インターフェースアダプターから渡された値を元にEntity層で定義されたビジネスロジックを実行します。
そして、アプリケーション特有のロジック(データ集計など)もここで行います。
本プログラムではクエリのベクトル化を行っています。
import { Injectable, Inject } from '@nestjs/common';
import type { IngredientRepository, RecipeRepository } from '../domain/repository.interface'
import { OllamaEmbeddings } from '@langchain/ollama';
import { Ingredient, RecipeInfo } from '../entities/recipe.entity';
@Injectable()
export class IngredientService {
private embeddings = new OllamaEmbeddings({
model: 'mxbai-embed-large',
baseUrl: "http://ollama:11434",
});
constructor(
@Inject('IngredientRepository')
private readonly ingredientRepository: IngredientRepository,
) { }
async searchIngredientByQuery(query: string): Promise<Ingredient[]> {
if (!query) {
throw new Error('検索クエリが空です');
}
// クエリをベクトル化
const vector = await this.embeddings.embedQuery(query);
// Repository を通して DB 検索
return await this.ingredientRepository.search(vector, 10);
}
}Domain(interface)層(図ではEntities層に含めてしまっています)ではEntitis層手前でInterfaceを定義しています。(ここで依存性の注入を行い、依存関係を正しい向きにするような処置をしています)
import { Ingredient, RecipeInfo } from "../entities/recipe.entity";
export interface IngredientRepository {
search(vector: number[], limit: number): Promise<Ingredient[]>;
}
Entity層では今回のシステムで使用するデータ(要素)を定義しています。
export class Ingredient {
constructor(
public document: string[],
public similarity: number,
) { }
}Infrasctructure層(フレームワークドライバー)では、データベースやWebなどの外側との接続をします。
import { Injectable } from '@nestjs/common';
// import type { RecipeRepository } from '../entities/recipe.repository';
import { IngredientRepository as IngredientRepositoryPort } from '../domain/repository.interface';
import { Ingredient, RecipeInfo } from '../entities/recipe.entity';
import { Pool } from "pg";
export type SearchResult = {
document: string;
similarity: number;
};
@Injectable()
export class PgIngredientRepository implements IngredientRepositoryPort {
private pool = new Pool({
user: 'postgres',
host: 'postgresql_vector',
database: 'recipe_db',
password: 'postgrespasswd1234',
port: 5432,
});
async search(vector: number[], limit: number): Promise<Ingredient[]> {
const client = await this.pool.connect();
try {
const result = await client.query(
`
SELECT document, 1 - (embedding <=> $1::vector) AS similarity
FROM langchain_pg_embedding
ORDER BY similarity DESC
LIMIT $2;
`,
[JSON.stringify(vector), limit],
);
console.log(result)
// pg の戻り値 rows は any[] なのでここで型を合わせる
// .map は「配列の各要素を変換する」処理
return result.rows.map(
(row: { document: string; similarity: number }) =>
new Ingredient([row.document], row.similarity),
);
} finally {
client.release();
}
}
}確認
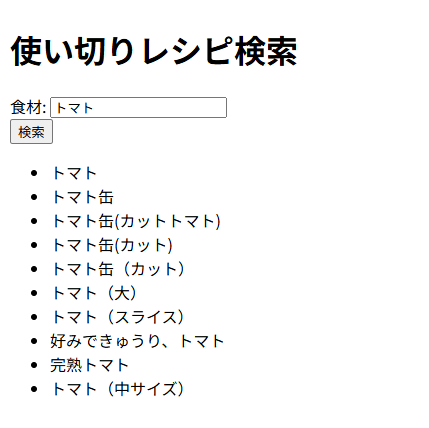
クエリとDB内のベクトルの類似度も求めるようにして、試しに「トマト」というクエリを検索してみると、バックエンドでDBに対して類似度の高いものを探します。
検索結果を求めると以下のようになります。
ref-voice-backend-container | { document: 'トマト', similarity: 1 },
ref-voice-backend-container | { document: 'トマト缶', similarity: 0.9714065313432038 },
ref-voice-backend-container | { document: 'トマト缶(カットトマト)', similarity: 0.9509795112356445 },
ref-voice-backend-container | { document: 'トマト缶(カット)', similarity: 0.9504187373061224 },
ref-voice-backend-container | { document: 'トマト缶(カット)', similarity: 0.9466150152732066 },
ref-voice-backend-container | { document: 'トマト(大)', similarity: 0.946173398759372 },
ref-voice-backend-container | { document: 'トマト(スライス)', similarity: 0.944389369778994 },
ref-voice-backend-container | { document: '好みできゅうり、トマト', similarity: 0.9381241460521428 },
ref-voice-backend-container | { document: '完熟トマト', similarity: 0.9375592656258306 },
ref-voice-backend-container | { document: 'トマト(中サイズ)', similarity: 0.9332998275848201 }そして、結果がfrontendに返されることで、ブラウザで検索結果が確認できました。
最後に
Clean Archetectureは結構抽象的でとっつきにくいイメージでしたが、実際に実装してみて感覚を掴めさえすれば、後はなんとかなりそうな感じではありました。
修正が必要になってくる可能性もありますが、とりあえず、実装しながら学ぶことができました。

