
はじめに
自作アプリで、本番環境に払い出そうとしたら、データを検索する際、DBからデータが表示されるまで凄い時間がかかりました。
そのため、色々と改善しました。
この記事はその記録になります。
改善(試しに探る)
まずは、100件に絞りました。
検索する際に、全てのデータを取ってこようとしているので、100件に絞ります。
これでも、ある程度、改善されたのですが、それでもかなり時間がかります。
次にGrafanaでかかっている時間を表示して確認しようとしました。
これはそもそもアプリ側で時間がかかっているのかDB側で時間がかかっているのかを切り分けておきたかったからです。
そして、以下のように表示されました。
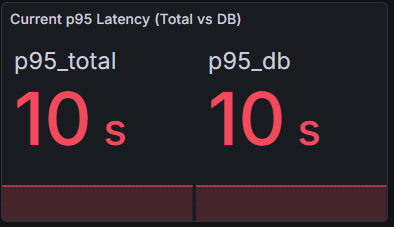
ここから分かるのは全体のアクセスは10秒以上かかっており、その内の10秒以上はDB側で起きているという事でした。
改善(原因の本質に迫る)
次に、実際に使っているSQLで時間がかかっている原因を調べてみます。
PostgreSQLにて、以下の実行をします。<実際のSQL文>には今回使用しているSQL文を入れます。
EXPLAIN (ANALYZE, BUFFERS)
<実際のSQL文>すると以下のような出力が出てきます。
Limit (cost=7024.95..10245140.73 rows=100 width=317) (actual time=6242.024..64879.744 rows=100 loops=1)
Buffers: shared hit=4588729 read=1250902, temp read=802 written=991
-> GroupAggregate (cost=7024.95..44235685.14 rows=432 width=317) (actual time=2762.494..61400.036 rows=100 loops=1)
Group Key: rs.priority_quantity, rs.score, r.recipe_id, rsalt.solt_name, rsalt.amzn_link
Buffers: shared hit=4588729 read=1250902, temp read=802 written=991
-> Incremental Sort (cost=7024.95..16280.02 rows=432 width=393) (actual time=1908.640..2767.599 rows=1081 loops=1)
Sort Key: rs.priority_quantity DESC, rs.score DESC, r.recipe_id, rsalt.solt_name, rsalt.amzn_link, (jsonb_build_object('food_alias_name', f.alias_name, 'ingredient_name', i.ingredient_name, 'amount_text', ri.amount_text, 'quantity_g', ri.quantity, 'kcal_per_g', n.kcal_per_g, 'protein_per_g', n.protein_per_g, 'fat_per_g', n.fat_per_g, 'carb_per_g', n.carb_per_g, 'similarity', ifm.similarity))
Presorted Key: rs.priority_quantity, rs.score, r.recipe_id, rsalt.solt_name, rsalt.amzn_link
Full-sort Groups: 29 Sort Method: quicksort Average Memory: 42kB Peak Memory: 42kB
Buffers: shared hit=97322 read=2, temp read=802 written=991
-> Nested Loop Left Join (cost=7003.51..16260.58 rows=432 width=393) (actual time=1878.225..2756.958 rows=1105 loops=1)
Join Filter: (ifm.food_id = n.food_id)
Rows Removed by Join Filter: 3109645
Buffers: shared hit=97317 read=2, temp read=802 written=991
-> Nested Loop Left Join (cost=7003.51..7346.08 rows=320 width=341) (actual time=1874.601..1915.149 rows=1105 loops=1)
Buffers: shared hit=97296 read=2, temp read=802 written=991
-> Nested Loop Left Join (cost=7003.23..7245.47 rows=320 width=309) (actual time=1874.575..1906.544 rows=1105 loops=1)内容を確認していくと、
- まず、一番上の行:Limit (actual time=6242.024..64879.744 rows=100 loops=1)ではこの1回のクエリで約65秒かかっていることが分かります。
- つまり、一回検索したら、65秒間待たないと結果が返ってこないということです。
🤔
- 次に2行目の
Buffers: shared hit=4588729 read=1250902, temp read=802 written=991です。- shared hitは共有バッファ(メモリ)にあったページを読んだ回数を示していて、それが450万ページ以上あることを示しています。
- ※PostgreSQLにはshared_buffers(共有バッファ)というメモリ領域があり、ここに最近使ったデータページをキャッシュしています。
- ディスクからの読み込みは125万ページです。
temp read / writtenが出ていて、一時ファイル(ディスク)を使った回数を示しています。- tempが出ていて、一時ファイルを使用しています。これは「work_mem不足 or 集約が重すぎ」であることを示しています。
- shared hitは共有バッファ(メモリ)にあったページを読んだ回数を示していて、それが450万ページ以上あることを示しています。
一番下の行、
Nested Loop Left Join (cost=7003.23..7245.47 rows=320 width=309) (actual time=1874.575..1906.544 rows=1105 loops=1)
で、まず 1105行作っています。
で、その次、
Nested Loop Left Join (cost=7003.51..16260.58 rows=432 width=393) (actual time=1878.225..2756.958 rows=1105 loops=1)
Join Filter: (ifm.food_id = n.food_id)
Rows Removed by Join Filter: 3109645
で、(actual time=1878.225..2756.958 rows=1105 loops=1)からもわかるように、3109645行試して、実際に取得した行は1105行でかなり無駄があります。
で、その次で、
Incremental Sort (cost=7024.95..16280.02 rows=432 width=393) (actual time=1908.640..2767.599 rows=1081 loops=1)
となり、ソートをしていて、1105→1081になって少し減っていることがわかります。
おそらくここは時間がかかっていません。
そして、やっと以下で100行に絞ります。
GroupAggregate (cost=7024.95..44235685.14 rows=432 width=317) (actual time=2762.494..61400.036 rows=100 loops=1)
インデックスの作成
以上より、今回はまず、インデックスを作成して検索を速くすることにしました。
以下のように、SQLをDBにて実施します。
recipe_db=# CREATE INDEX CONCURRENTLY IF NOT EXISTS idx_recipe_processes_recipe_id
ON recipe_processes (recipe_id);
CREATE INDEX
recipe_db=# CREATE INDEX CONCURRENTLY IF NOT EXISTS idx_recipe_process_tips_recipe_id_process_num
ON recipe_process_tips (recipe_id, process_num);
CREATE INDEXこれで、66秒→6秒に短縮しました!
クエリの分割
次にクエリを分割しました。まず一つ目のクエリで100件まで検索で求めてから、次のクエリとして、条件の加工部分、JOINとJSON_AGGを実施するようにしました。
しかし、それでも5秒ぐらいかかりました。
6秒→5秒に改善。
データ取得のタイミングを分ける
最後にデータを取ってくるタイミングを分割しました。
検索のタイミングでレシピの一覧だけでなく、レシピの材料やレシピの手順の全てを取ってこようとしていました。
ここのタイミングを検索時にはレシピの一覧を取得しようと思いました。
そのほかのデータはレシピの詳細を開くタイミングで取得して表示するような実装としました。
これで、1秒もかからなくなりました。
最後に
オブザーバビリティを最初に導入するというのはとてもいいことだと思います。
しかし、サービスの初期段階ではオーバースペックな実装になりそうです。
このため、まずはアクセス時間の取得など、細かいところから分かるようにした方がいいのだろうと、今回の改善を通して思いました。

