
はじめに、
こんちはー。
さて今回はスクレイピングをやってみるシリーズの第1回目シリーズです。前回の記事はスクレイピングとはなんぞやという基礎的なところから記事に書きました。以下になるので良ければ読んでみてください。
そして、今回は実際にスクレイピングをしてみるという事なのですが、できるだけ丁寧に書いていきます。実際にコードを書きながらここはこういう意味だという事を一つ一つ書いていければ良いかなと思っています。
今回作るのはNetflix Originalの作品の中から評価の高い映画を抽出しようというものです。
今、最も勢いに乗っているサブスク型動画配信サービスNetflix。しかも、このNetflixのすごいところは何といってもNetflix自身でも映画を作成しているというところ。
しかし、一方で、Netflix originalの作品の評価はyahoo映画やfilmarksのような映画評価サービスではなかなか面白さの指標としては明確に確かな基準がありません。yahoo映画では評価されていない作品もありますし、filmarksは結構ラフな評価もあってなかなかこれ以上取れていれば面白いなと思えるような基準がないんです。(あくまで個人の感想です)
ちなみにyahoo映画に関しては★3.6以上あれば面白いと思える作品だと個人的には思ってます。過去の経験則ですが、過去に僕は年300本以上観る年もあったのでそれなりに信用できる指標かと自負しております。
では、Netflix originalの作品の評価を調べるためにはどうするかと言うと、Rotten Tomatoesというサイトを使うといいと思います。Rotten Tomatoesとは後述しますが海外の映画評価サイトです。かなり信用できる評価値が得られますが、海外のサイトなのでタイトルは原題(英語表記)で調べる必要があります。
つまり、まず日本語タイトルで原題を調べ、その原題を元に検索をかけてその映画の評価を調べる必要があります。これ、結構地味にめんどいです。好評価されているにも関わらず、知らないままの映画作品がある可能性もあり、そんな作品を見つけたいなと思いました。
そこで今回はそんな作品たちを見つけるためにスクレイピングをしてみようとしてみようという事です。
前置きが長くなってしまい申し訳ございません。それでは早速いってみましょう。
使用するWebページ
今回使用するwebサイトは以下になります。Rotten Tomatoesでは原題表記なので原題表記の一覧が得られるサイトになってます。
2015~2017年のNetflix Originalの作品一覧が載っているwikipedia

2018年のNetflix Originalの作品一覧が載っているwikipedia

2019年のNetflix Originalの作品一覧が載っているwikipedia

2020年のNetflix Originalの作品一覧が載っているwikipedia

2021年のNetflix Originalの作品一覧が載っているwikipedia

Rotten Tomatoes

Rotten Tomatoes とは
Rotten Tomatoesは映画評論家のレビューをまとめたサイトで、映画にとどまらず、テレビドラマの作品も評価の対象になってます。
評価値は映画評論家だけでなく一般の人の評価値も出ています。Tomatometerが映画批評家の評価値でAudience Scoreが一般の人の評価値ですね。
Tomatometerは60%以上の評価でFreshといってトマトのアイコンになります。60未満はRottenといって腐って潰れたアイコンになってます。
Audience Scoreも同様に60%を基準にアイコンが変わります。60%以上の評価でポップコーンが立っていて、60%未満の評価でポップコーンが倒れています。
詳しくはいつかまとめたいと思います。今は信用できる評価サイトで60%を基準に評価が変わっているというところの理解で大丈夫です。
設計
今回の実行の手順(設計)としては
- wikipediaのnetflix original映画一覧をスクレイピングで取得
- 取得した映画一覧データを元にrotten tomatoesにアクセスして評価の値を取得
- 取得した評価の値から値の高い映画を求める
といった流れで進めたいと思います。
robots.txtを確認してアクセスしていいかを確認
これは前回の記事でも記載した通り、アクセスしてはいけないところをチェックしましょう。つまりスクレイピングが禁止されているところの確認です。最初にもリンクは載せましたが、前回の記事は以下から行けます。

すると以下のようなページになると思います。
User-agent: *
Disallow: /search
Sitemap: https://www.rottentomatoes.com/sitemap.xmlwikipediaも同様に見てみましょう。以下のリンクから確認できます。

長いので割愛しますが、今回対象にするサイトに関してはアクセスは問題ないようです。
手順1.「wikipediaのnetflix original映画一覧をスクレイピングで取得」
さて本題です。今回はwikipediaのnetflix originalの一覧をdataframeとして取得します。
今回のプログラミングのコードはjupyter notebookを使用してpythonで書いてます。
試しに2015~2017年のNetflix Originalの作品一覧が載っているwikipediaのページのリストをDataframeとして取得しましょう。他の2018年だったり2019年などのwikipediaのページも同様の処理なのでそちらのページの取得に関しては割愛します。
以下のコードになります。めっちゃシンプル。
import pandas as pd
url = "https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2015%E2%80%932017)"
df = pd.read_html(url)
df[0]1行目でpandasというモジュールをインポートしてpdとして使う事を示しています。これはおまじないだと思ってもらって大丈夫です。pandasにある機能を使って今回の処理を実現するというイメージです。
2行目で今回の対象のページのURLをurlという変数に入れてます。
3行目でread_html()を用いてデータを取得します。取得した値はDataFrame型として格納されます。
最後に4行目でdfを表示します。結果は以下のように出力されるかと思います。
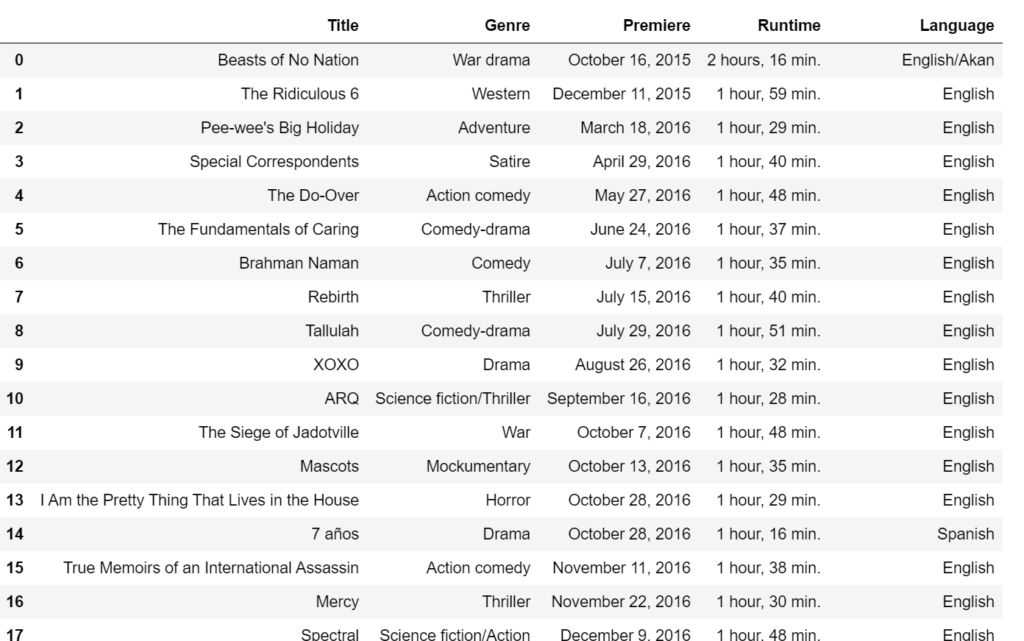
対象のwikiのページ(https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2015%E2%80%932017))を見てみるとわかるのですが、表は3つあります。上記で出力したのは1つ目の表になります。対象のページでいうとFeature filmsというタイトルの表になります。
Documentariesの表はdf[0]でなくdf[1]の方に格納されています。試しに上記のプログラムの4行目をdf[0]からdf[1]に変更してみてください。Documentariesの表が出力されるはずです。
はい、以上でDataFrameの取得が完了です。
結構簡単ですね。pythonさまさまって感じです。
まとめ
今回は、オリエンテーション的な内容になりましたが、まず、調べる元となる映画作品一覧を取得できました。
次回は実際にRotten Tomatoesにアクセスして評価値を取得、そしておすすめ作品の一覧を作っていきたいと思います。

