
はじめに + 今回すること
どうも、こんにちは、這須ダス太(ハウスダスタ)です。
私はみます。
昔は時間があったので、その時間を全て映画につぎ込んでいたと言っていいほど映画を観ていました。
しかし、現在、映画を観るとなると2時間強の時間が必要になってしまい、中々観れていません。
家でサブスクというNetflixですら、時間があまり取れません。
限りある時間の中で、本当に自分にとって面白いと思える作品に出会えることがとてもかけがえのないものだと思うようになってきました。
そこで、今回はNetflixの映画でRotten Tomatoの評価が高い上位10作品を求めてみようと思います。
以前、Rotten Romatoから値を取得したことがあります。
こちら👇の2つの記事です。
で、今回はrotten-tomatoes-scraperがサポート終了していることもあり、自分で取得して見ようと思います。
rotten tomatoの値を取得しようとした際に、
- kaggleのNetflixデータを使用する方法
- pythonのlibrary「rottentomatoes-python」を使用する方法
が候補として挙がりました。
しかし、この二つの方法には問題があり、試行錯誤もしたりしたのですが、結果的に上手くいかなかったので、どうして上手くいかなかったかも記載しておこうと思います。
kaggleのNetflixデータでの失敗
kaggleとは機械学習やデータサイエンスに携わっているエンジニアのプラットフォームで、学習用のデータが手に入ったりします。
この中で、Netflixのデータがあったので使おうと思いました。
しかもRotten Tomatoの点数のデータも入っているので、自分で集めなくてもいいじゃんと思いました。
で、このNetflixデータNetflix original以外の作品も入っていました。
例えば、「K-on! the movie」。配信されていたら含めたんですかね。
更に、この「K-on! the movie」観客のスコアが100なんですよね。
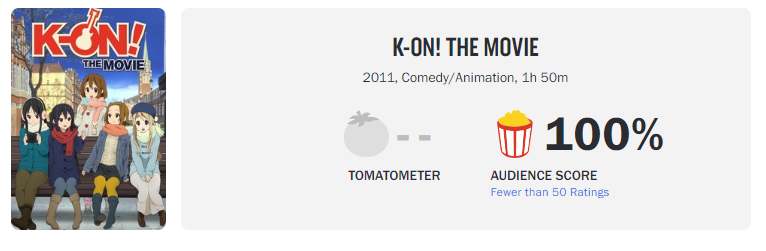
その理由はレビュー数かと思われます。
レビュー数は50件以下。
レビュー数が少ないため、特定のファンが全て100点を付ける事でこのような結果になっているように見えます。
pythonのlibrary「rottentomatoes-python」での失敗
pythonのlibraryにrottentomatoes-pythonというものを見つけました。

結構よさげかと思って使ったのですが、かなり上手くいかず悶絶しました。
多数のデータを取得する必要があるので、私はラズベリーパイのバックグラウンドでプログラムを実行し値を取得しようとしているのですが、何故かラズパイだと以下のように
File "/home_dir/.local/lib/python3.7/site-packages/rottentomatoes/search.py", line 76, in top_movie_result
raise LookupError("No movies found.")
rottentomatoes.exceptions.LookupError: No movies found.
この発生条件がよくわからず、上手く取得できる時とできない時があります。
あと、SSLエラーがでます。
ライブラリ内部のコードで発生するので、コードを変えるのも怖いです。
以上2つの失敗を踏まえて以下の条件で値を収集しようと思います。
- 作品タイトル一覧はWikipediaの一覧から取得する
- ライブラリなどは使わず、直接Rotten Tomatoから値を取得するプログラムを書く
- レビュー数に閾値を設けて、その閾値を満たす作品の値の点数をもとめる
- TomatometerとAudienceの両方の値を取得する
実践🍅

Rotten Tomatoとは海外の映画レビューサイトです。
このサイトは映画評論家の評価と観客の評価の両方を見れることが特徴となります。
ですので、結構、評価の値は信憑性があります。
プログラム
今回のプログラムは以下のようにしています。
import pandas as pd
import re
import requests
from bs4 import BeautifulSoup
import time
import datetime
urls = [
"https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2015%E2%80%932017)",
"https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2018)",
"https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2019)",
"https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2020)",
"https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2021)",
"https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2022)",
"https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(since_2023)"
]
#df_initial = pd.read_html("https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2015%E2%80%932017)")
df_list = []
count = 0
for url_item in urls:
code_1 = 'df_{} = pd.read_html(url_item)[0]'.format(count)
print(count)
code_2 = 'df_list.append("df_{}")'.format(count)
count = count + 1
exec(code_1)
exec(code_2)
print(type(df_0))
#print(df_list)
result_df = pd.concat([df_0, df_1, df_2, df_3, df_4, df_5, df_6], ignore_index=True)
print(result_df.shape)
tomato_dict = {}
count = 0
result_df = result_df.drop(0, axis=1)
result_df = result_df.drop(1, axis=1)
result_df = result_df.drop(0, axis=0)
#print(result_df)
base_tomato_url = "https://www.rottentomatoes.com/m/"
for index, row in result_df.iterrows():
try:
print("-----------------------------")
time.sleep(15)
title_item = row['Title']
#print(title_item)
premiere_day = row['Premiere']
original_title = title_item.replace(' ', '_').lower()
original_title = re.sub(r'\[[^\]]*\]', '', original_title)
print(original_title)
url = base_tomato_url + original_title
premiere_day = re.sub(r'\[[^\]]*\]', '', premiere_day)
year = re.findall('\S\d\d\d', premiere_day)
title_with_year = original_title + "_" + year[0]
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
tomatometer_score = soup.find('score-board', {'id':'scoreboard'})['tomatometerscore']
tomato_review_count = soup.find('a', {'data-qa':'tomatometer-review-count'}).get_text().replace("\n", "")
audience_score = soup.find('score-board', {'id':'scoreboard'})['audiencescore']
audience_review_count = soup.find('a', {'data-qa':'audience-rating-count'}).get_text().replace("\n", "")
tomato_dict[str(count)] = { \
'title' : title_item, \
'premiere_day': premiere_day, \
'tomatometer_score': tomatometer_score, \
'tomato_review_count': tomato_review_count, \
'audience_score' : audience_score, \
'audience_review_count': audience_review_count \
}
count = count + 1
except Exception as e:
print(f"year error, {title_item}: {e}")
try:
url = base_tomato_url + title_with_year
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
tomatometer_score = soup.find('score-board', {'id':'scoreboard'})['tomatometerscore']
tomato_review_count = soup.find('a', {'data-qa':'tomatometer-review-count'}).get_text().replace("\n", "")
audience_score = soup.find('score-board', {'id':'scoreboard'})['audiencescore']
audience_review_count = soup.find('a', {'data-qa':'audience-rating-count'}).get_text().replace("\n", "")
tomato_dict[str(count)] = { \
'title' : title_item, \
'premiere_day': premiere_day, \
'tomatometer_score': tomatometer_score, \
'tomato_review_count': tomato_review_count, \
'audience_score' : audience_score, \
'audience_review_count': audience_review_count \
}
count = count + 1
except Exception as e:
print(f"other error, {title_item}: {e}")
except Exception as e:
print(f"other error, {title_item}: {e}")
まず、wikipediaでNetflix作品の一覧を取得します。
その後、タイトルごとに一つ一つ見ていきます。
今回はレビュー数も取得の際の注意ポイントとしてデータを集めました。(後でフィルタリングをします。)
で、Rotten Tomatoは気を付けないと結構な頻度でAccess Deniedになるので、今回は15秒というとても長いインターバルを設けています。
つまり、一回ページを閲覧したら15秒間待機して、次のページにアクセスするという処理にしています。
結果
結果です。
まずはTomatomaterのスコアから
1位:プリジョネイロ(原題:7 Prisoners):98%
1位:西部戦線異状なし(原題:All Quiet on the Western Front):98%
3位:ハーフ・オブ・イット: 面白いのはこれから(The Half of It):97%
3位:ルディ・レイ・ムーア(Dolemite Is My Name):97%
5位:ROMA/ローマ(Roma):96%
6位:クロース(Klaus):95%
6位:アイリッシュマン(The Irishman):95%
6位:マリッジ・ストーリー(Marriage Story):95%
6位:最悪の選択(Calibre):95%
6位:ジェイコブと海の怪物(The Sea Beast):95%
11位:ニモーナ(Nimona):94%
11位:パワー・オブ・ザ・ドッグ(The Power of the Dog):94%
11位:プライベート・ライフ(Private Life):94%
11位:ゼイ・クローン・タイローン ~俺たちクローン?(They Cloned Tyrone):94%
15位:シー・ユー・イエスタデイ(See You Yesterday):93%
15位:泣きたい私は猫をかぶる(A Whisker Away):93%
15位:カムガール(Cam):93%
18位:ザ・ストレンジャー(The Stranger):92%
18位:セットアップ: ウソつきは恋のはじまり(Set It Up):92%
18位:ずっとあなたを待っていた(Been So Long):92%
続いてAudienceのスコアです。
1位:ビヨンド・ザ・ユニバース(Beyond the Universe)96%
1位:クロース(Klaus):96%
3位:ザ・ダート: モトリー・クルー自伝(The Dirt):94%
3位:ライトニング・ムラリ(Minnal Murali):94%
5位:ザ・ハーダー・ゼイ・フォール: 報復の荒野(The Harder They Fall):93%
5位:ちひろさん(Call Me Chihiro):93%
7位:レッド・ノーティス(Red Notice):92%
7位:ヒルダと山の王(Hilda and the Mountain King):92%
7位:クレイジーなくらい君に夢中(Crazy About Her):92%
10位:JOGI -街が炎に包まれた日-(Jogi):91%
10位:ソウル・バイブス(Seoul Vibe):91%
10位:ニモーナ(Nimona):91%
10位:ドールハウス 〜想いをこめて(Doll House):91%
10位:ルディ・レイ・ムーア(Dolemite Is My Name):91%
15位:グレイマン(The Gray Man):90%
15位:シカゴ7裁判(The Trial of the Chicago 7):90%
15位:ラブ・ハード(Love Hard):90%
15位:いつだって友達止まり(Friendzone):90%
15位:サマーキャンプ(A Week Away):90%
15位:さえない私にさようなら(Faraway):90%
考察
wikipediaから取得した映画の作品の数は739でしたが、実際に値が取得できた作品の数は525でした。
200本以上の作品はエラーなどで取得できなかったことになります。
大きな原因としては以下のようなエラーで値が取得できなかったところにあります。
zom_100:_bucket_list_of_the_dead
year error, Zom 100: Bucket List of the Dead: 'NoneType' object is not subscriptable
other error, Zom 100: Bucket List of the Dead: 'NoneType' object is not subscriptable
the_(almost)_legends year error, The (Almost) Legends: 'NoneType' object is not subscriptable other error, The (Almost) Legends: 'NoneType' object is not subscriptable
お分かりのように、タイトルに記号(黄色いマーカー部分)が入っていると、urlが存在せずにエラーになってしまっています。
ですので、これらの記号に対応できるようにプログラムを改修していく必要があります。
まとめ
今回はkaggleのデータやら、ライブラリがうまく動かないやらで結構時間がかかりました…。
それでも、200件以上の映画情報が取れませんでした。
再度、リベンジして、分析をしてみたいと思います。
今回はここまで。ではまた。👋👋👋

