はじめに
この検索では使い切りたい食材を入力するのですが、スクレイピングしてきたレシピなので、同じ食材でも食材の名前が微妙に変わります。
例えば、「鶏むね肉」や「鶏胸肉」や「とり胸肉」など。
日本語ってめんどくさいですね。
そこで、ローカルLLMというかベクトルDBを用いて類似検索をすることを試みました。
要は、RAGを作ろうとしました。
今回は、RAGの最初のベクトル化のところまでの実装の記録です。
💀実は、、、
話が少しずれるのですが、実は、、、データが飛びました💀💀💀
wslのディストリビューションを誤って削除してしまい、データが吹っ飛んでしまいました。
なので、作り直しです。
ほぼ1から。
で、もともと、frontendにvue.jsとbackendにdjangoを設け、DBはmysqlを使用していました。
しかし、まっさらになったからには勉強の意味も含めて、frontendにreactを使用し、frontendとbackendにtypescriptを使用した構成にしようと思いました。
DBはベクトル化ができるpostgresqlを採用することにしました。
RAGとは
さて、話を戻しましょう。
まずは、RAGとはなんぞやというところから。
RAG(Retrieval-Augmented Generation、検索拡張生成)とは「検索」と「生成AI」を組み合わせた仕組みのことで、自分のデータベース(文書やナレッジベースなど)から関連する情報を検索(Retrieval)して、検索結果をもとに、生成AIが自然な文章で回答(Generation)を作成します。
実装の流れとしては、以下になります。
— データの登録 —
Embedding (Document)
⇓
Vector DBにデータを追加
— 質疑応答 —
Embedding (query)
⇓
検索(コサイン類似度やユークリッド距離を使う)
⇓
統合
⇓
生成(LLM)
大きく二つのフェーズに分かれ、1つ目はデータの登録します。
Embeddingという言葉や文章などを「意味を保ったまま数値(ベクトル)」に変換する技術をもちいてベクトルへの変換を行います。(ここでEmbeddingが2つ出てきたところがややこしかったです)
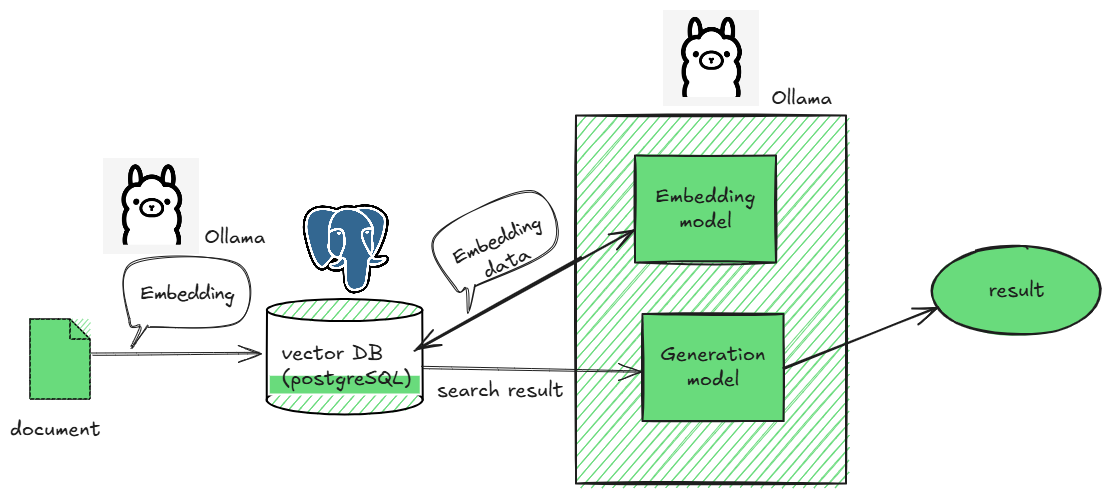
今回はEmbeddingとLLMにはOllamaを使用し、Vector DBにはPostgreSQLを使用するので、以下のような流れになります。(※この記事ではLLMまでは実装しません。)
— データの登録 —
Embedding (Document) / Ollama
⇓
Vector DBにデータを追加 / PostgreSQL
— 質疑応答 —
Embedding (query) / Ollama
⇓
検索(コサイン類似度やユークリッド距離を使う)
⇓
統合
⇓
生成(LLM)/ Ollama
図にすると以下のようになります。
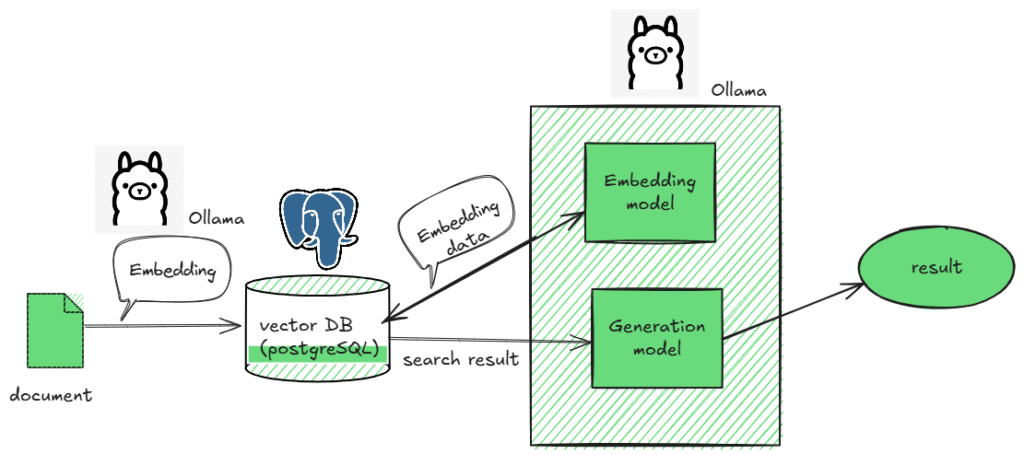
データの登録
まずはデータの登録からやってみます。
— データの登録 —
Embedding (Document) / Ollama
⇓
Vector DBにデータを追加 / PostgreSQL
のところです。
pythonで以下のコードを使って、ベクトルDBに登録を行います。
from langchain_postgres import PGVector
from langchain_ollama import OllamaEmbeddings
from langchain_core.documents import Document
import psycopg2
# Embedding モデル(Ollama)
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# PostgreSQL + PGVector 接続設定
connection = "postgresql+psycopg://postgres:postgrespasswd1234@localhost:5432/recipe_db"
# 既存の ingredients テーブルから材料を取り出す
conn = psycopg2.connect("dbname=recipe_db user=postgres password=postgrespasswd1234 host=localhost")
cur = conn.cursor()
cur.execute("SELECT ingredient_id, ingredient_name FROM ingredients;")
rows = cur.fetchall()
cur.close()
conn.close()
# LangChain の Document に変換
docs_ing = [
Document(page_content=row[1], metadata={"ingredient_id": row[0]})
for row in rows
]
# PGVector に保存(既存コレクション削除 → 作り直し)
ingredient_vectorstore = PGVector(
embeddings=embeddings,
collection_name="ingredients",
connection=connection,
use_jsonb=True,
pre_delete_collection=True,
)
# ベクトルDBに追加
ingredient_vectorstore.create_collection()
ingredient_vectorstore.add_documents(docs_ing)ここで、ollama側のコンテナにはEmbedding用にmxbai-embed-largeモデルを入れておかなければなりません。
なので、ollama側のコンテナ内に入って以下を実行します。
ollama pull mxbai-embed-large確認してみる

確認してみましょう。
ここでは、以下までを疑似的に実施します。
— 質疑応答 —
Embedding (query) / Ollama
⇓
検索(コサイン類似度やユークリッド距離を使う)
使うpythonコードは以下。
from langchain_ollama import OllamaEmbeddings
import psycopg2
# 1. クエリをベクトル化 (Ollama を利用)
embeddings = OllamaEmbeddings(model="mxbai-embed-large") # ローカル埋め込みモデル
query = "トマト"
query_vec = embeddings.embed_query(query)
# 2. PostgreSQL に接続
conn = psycopg2.connect(
"dbname=recipe_db user=postgres password=postgrespasswd1234 host=localhost"
)
cur = conn.cursor()
# 3. コサイン類似度で検索
cur.execute("""
SELECT document, 1 - (embedding <=> %s::vector) AS similarity
FROM langchain_pg_embedding
ORDER BY similarity DESC
LIMIT 10;
""", (query_vec,))
rows = cur.fetchall()
for doc, sim in rows:
print(sim, doc)
cur.close()
conn.close()実行結果は以下のようになりました。
$ test/bin/python3 postgresql_vector/python_codes/check_embedding.py
1.0 トマト
0.9714065313432038 トマト缶
0.9509795112356445 トマト缶(カットトマト)
0.9504187373061224 トマト缶(カット)
0.9466150152732066 トマト缶(カット)
0.946173398759372 トマト(大)
0.944389369778994 トマト(スライス)
0.9381241460521428 好みできゅうり、トマト
0.9375592656258306 完熟トマト
0.9332998275848201 トマト(中サイズ)ちなみに「トマト」ではなく「とまと」であれば、
0.8328490358625038 トマト缶(カット)
0.8295095417343065 トマト缶(カットトマト)
0.8283459562018309 トマト(スライス)
0.8269667871884173 トマト缶(カット)
0.8255633171343978 トマト
0.8237194944264377 好みできゅうり、トマト
0.8219543246221511 トマトカット缶
0.8149894651814676 トマト(大)
0.8137156922472801 トマト缶(又は紙パック)
0.8108799199677362 完熟トマトとなってしまい、希望の「トマト」の類似度は下がってしまいます。
ここが日本語のめんどくさいところです。
最後に
ベクトル化のDBへの登録を行い、実際にベクトルによる類似検索までの確認ができました。
今後、RAGにするため、LLMの実装も試みたいと思っています。


