
はじめに
英語のpdf資料を翻訳機にかけようとして、やりにくいなって思ったことありませんか?
例えば、Googleの親会社Alphabetの2024年1Qの決算のpdfの最初を翻訳機にコピペすると以下のようになる。以下はDeepLにコピペした結果です。
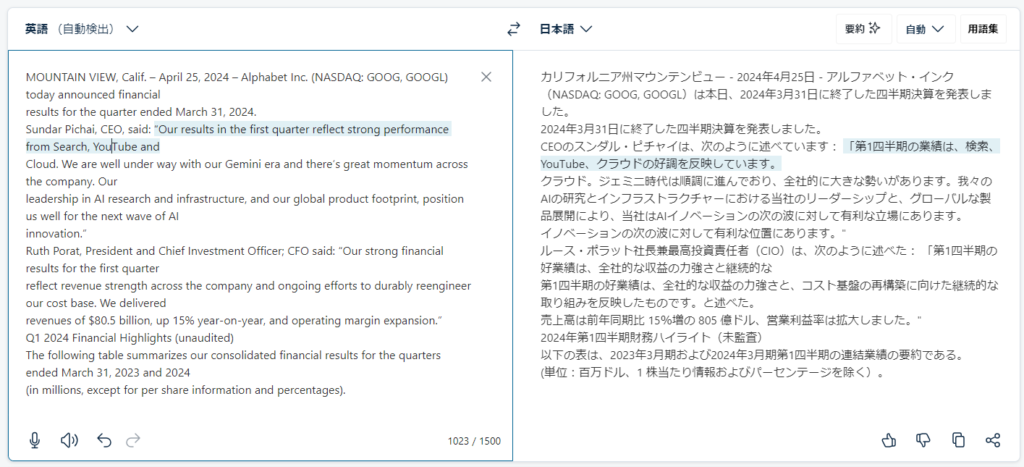
文字面は以下のような感じ。
MOUNTAIN VIEW, Calif. – April 25, 2024 – Alphabet Inc. (NASDAQ: GOOG, GOOGL) today announced financial
results for the quarter ended March 31, 2024.
Sundar Pichai, CEO, said: “Our results in the first quarter reflect strong performance from Search, YouTube and
Cloud. We are well under way with our Gemini era and there’s great momentum across the company. Our
leadership in AI research and infrastructure, and our global product footprint, position us well for the next wave of AI
innovation.”
Ruth Porat, President and Chief Investment Officer; CFO said: “Our strong financial results for the first quarter
reflect revenue strength across the company and ongoing efforts to durably reengineer our cost base. We delivered
revenues of $80.5 billion, up 15% year-on-year, and operating margin expansion.”
Q1 2024 Financial Highlights (unaudited)
The following table summarizes our consolidated financial results for the quarters ended March 31, 2023 and 2024
(in millions, except for per share information and percentages). pdfが改行されているところは改行されてしまっています。
これを一文ごとにしようというのが今回の試みです。
pythonコードにする
ということでpythonでそのコードを書いてみました。
コードとしてはピリオドまでを一文として取り出すようにしています。
それをテキストに保存するまでします。
以下がそのコードです。
from pypdf import PdfReader
import re
def extract_text_from_pdf(pdf_path):
pdf_reader = PdfReader(pdf_path)
text = ''
for page in pdf_reader.pages:
text += page.extract_text()
sentences = re.findall(r'\b[^.]+\.', text)
return sentences
input_pdf = '/input/pdf/file/path'
text_list = extract_text_from_pdf(input_pdf)
for i in range(len(text_list)):
text_list[i] = text_list[i].replace('\n', ' ')
text_list[i] = re.sub(' +', ' ', text_list[i])
text = '\n'.join(text_list)
with open('/output/text/file/path','w') as file:
file.write(text)実行結果
PDFファイルの以下の部分の実行結果を見てみます。

実行し、出力された結果は以下のようになりました。
Alphabet Announces First Quarter 2024 Results MOUNTAIN VIEW, Calif.
April 25, 2024 – Alphabet Inc.
NASDAQ: GOOG, GOOGL) today announced financial results for the quarter ended March 31, 2024 .
Sundar Pichai, CEO, said: “Our results in the first quarter reflect strong performance from Search, YouTube and Cloud.
We are well under way with our Gemini era and there’s great momentum across the company.
Our leadership in AI research and infrastructure, and our global product footprint, position us well for the next wave of AI innovation.
Ruth Porat, President and Chief Investment Officer; CFO said: “Our strong financial results for the first quarter reflect revenue strength across the company and ongoing efforts to durably reengineer our cost base.
We delivered revenues of $80.
5 billion, up 15% year-on-year, and operating margin expansion.ちゃんとピリオドで一文にはなっていますね。
小数点などもピリオドと判断されてしまっていますが。。。
これを翻訳機にコピペすると、、、
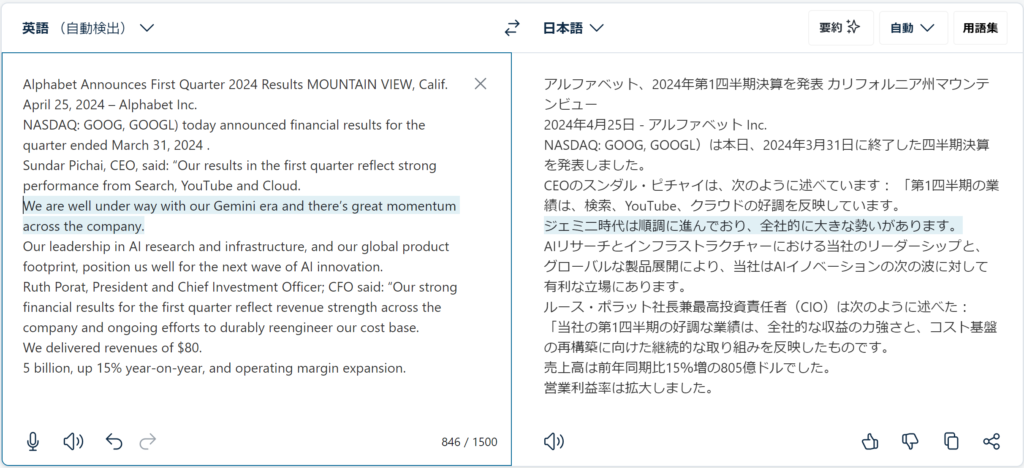
結構、ちゃんと訳されているのではないでしょうか。
小数点のところも一文にまとめられて訳されています。これはDeepLの能力が高いおかげかも?
ま、まあ、これで英語PDFは扱いやすくなるんじゃないのかな。
今後の改良
現状の課題として、
- 小数点の数字、アドレスのドットなどの一文の終わりではないピリオドで一文が終わってしまうこと
- タイトルなどのピリオドで終わらない文が次の行に結合されてしまっていること
が挙げられます。
余裕があればコードを更新させます。。。

