
前回まででディズニーランドとディズニーシーの待ち時間をランダムフォレストによって予測できるかを試してみました。
結果はイマイチな結果になってしまいました。
今回はこの結果の改善できるかを試してみようと思います。
改善点
まず、前回までの改善点ですが、以下が挙げられます。
- 天気の情報パラメータが少ない
- ⇒ 今回は気象庁の天気のデータを使いましたが、値にnullが多く、且つパラメータ自体も少なかったです
- イベントをダミー変数として使っていない
- ⇒ イベントがあるかどうかとイベント数を変数でしか使っていなかったです。
- もし、特定のイベントが発生すると待機時間が長くなったりする場合があったら対応できないです
- ディズニーランド/シー側のデータも少ない
- ⇒ 1年分のデータしか使っていないので、もっとデータが欲しいと思いました
改善策
上記改善点に対して、各改善策は以下のようになりました。
- 天気の情報パラメータが少ない
- ⇒ OpenWeather APIのOne Call API 3.0を使用する
- これにより過去の天気情報を取得できる
- One Call API 3.0は有償ではあるが、一日1000リクエストまで無料なので無料枠で対応する
- ドキュメントは⇒こちら
- ⇒ OpenWeather APIのOne Call API 3.0を使用する
- イベントをダミー変数として使っていない
- ⇒ ダミー変数化しました
- ディズニーランド/シー側のデータも少ない
- ⇒ プラス3ヶ月分データを追加しました
OpenWeather APIのOne Call API 3.0に関して各レスポンスのパラメータは以下の値となります。
temp:気温(K)
feels_like:人間の感じる温度(K)
pressure:気圧(hPa)
humidity:湿度
dew_point:結露し始める点
clouds:曇りの度合い(%)
visibility:大気の混濁の程度を表す量(目視観測で適当な目標が肉眼によって認め得る最大距離)
wind_speed:風速
wind_deg:風向き
結果
上記の内容を踏まえてランダムフォレスト実行します。
ランダムフォレストによる学習ではnanのデータは使えないので、それらを省くと結果的に984データで学習することになりました。
ランダムフォレストの結果
ランダムフォレストを実施すると以下の結果になりました。
学習データに対する回帰への評価(RMSEの値): 11.230263182576643
学習データに対する決定係数: 0.9280434231304977
テストデータに対する回帰への評価(RMSEの値): 26.54488614271964
テストデータに対する決定係数: 0.6024229019442858
テストデータによる評価は決定係数が0.602程でしたが、前回の結果は0.516程だったので、少し改善できたのかと思います。
重要度が高いパラメータは以下のようになりました。
happy_ride : 0.31346757552693166
monsters_inc : 0.10505510638607571
feels_like : 0.0636213366134936
splash_mountain : 0.06226238901146833
dew_point : 0.05658816757521617
pressure : 0.04365605709818174
temp : 0.03245041237897116
woodchuck_donald : 0.028292410612989406
star_tuors : 0.027578229279425562
東京都立高校推薦入試 : 0.02726068919844422
重要度自体は高くありませんが、天気のパラメータが上位に入っていることが分かります。
- feels_like
- dew_point
- pressure
- temp
ここで、実測値と予測値の比較グラフを表示してある事に気づきました。
以下が実測値と予測値の比較グラフです。
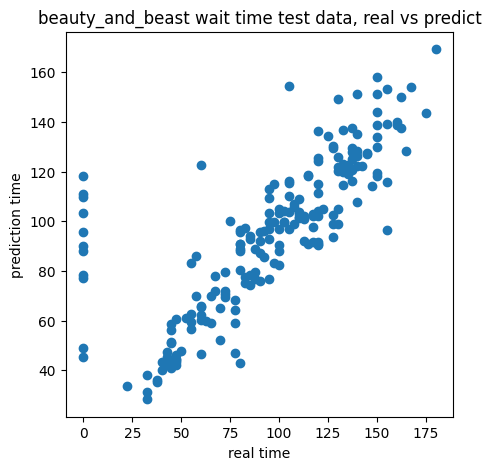
実際の値が0のところに予測値では値が出てしまっています。
今回集めたデータは休止中はnanとしてデータを扱っているのですが、「-」という値の時が稀にあって、その時は値を0にしていました。
実際これは値が取れなかっただけの可能性もあります。
ですので、0の値のところは無視して再度学習をさせてみる事にしました。
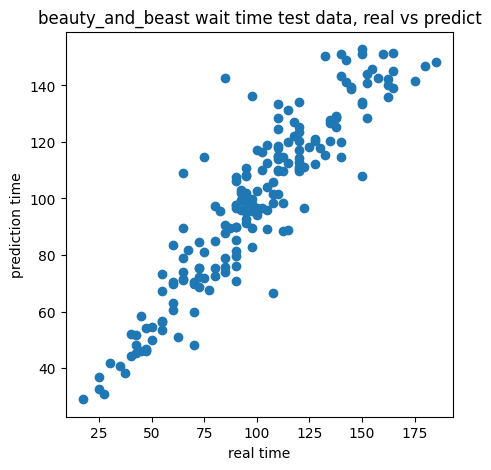
以下が結果です。
学習データに対する回帰への評価(RMSEの値): 6.198378858406017
学習データに対する決定係数: 0.9706435388652599
テストデータに対する回帰への評価(RMSEの値): 14.137855744552052
テストデータに対する決定係数: 0.8386963310917938
めちゃくちゃ精度が上がりました!!
改善後の実測値と予測値の比較です。
改めて重要度が高いパラメータも求めました。
happy_ride : 0.4955585737138789
monsters_inc : 0.1456266478950504
splash_mountain : 0.05718033031761465
dew_point : 0.04783843744684448
star_tuors : 0.04426888045372924
feels_like : 0.04078277087802022
temp : 0.027555634909747675
minnie_style_studio : 0.022921053324998594
woodchuck_donald : 0.015153232492450508
humidity : 0.012252518686310263
結構、天気のパラメータが入りましたね。
全体の重要度の関係
ランダムフォレストの結果の重要度の関係図も求めました。線が太い方が重要度が高い事を示しています。
また、重要度が低いものは省いています。
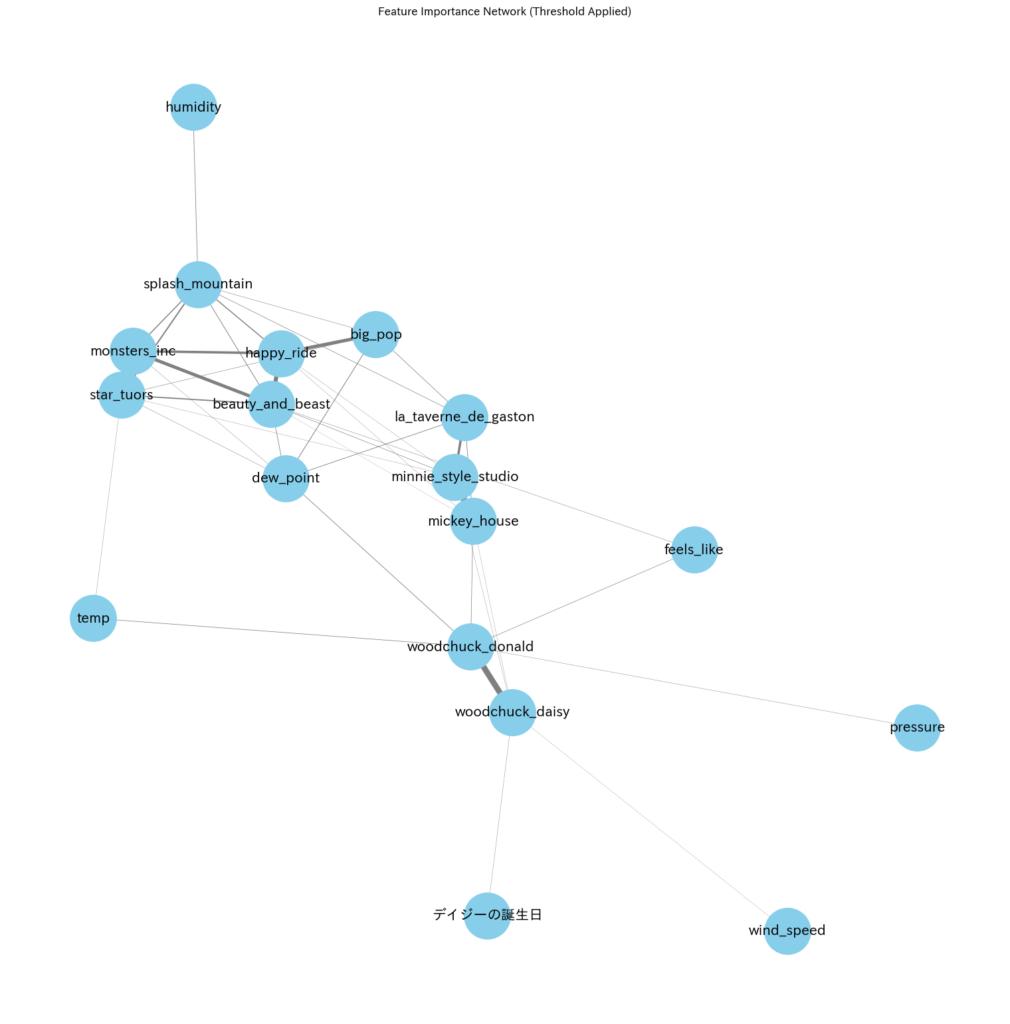
図にしてみると、dew_pointが幾つかのアトラクションの待ち時間に影響していることが分かります。
これは、結構以外で、結露し始める点で待ち時間が多く左右されることを示します。
最後に
改善できてよかったです。
まだデータ量は少ないので、また時間が経ってから再度学習させてみたいです。
