
今回すること
前回の映画の分類では20個の分類で分けました。
今回は分類を増やして試したいと思います。
また、似た映画として
Word2Vecの結果からコサイン類似度を用いて求めてみます。
また、
- overveiw(概要)
- keywords(キーワード)
- genres(ジャンル)
の3次元で分類した結果の空間の距離とコサイン類似度から似た映画がどんな作品として出てくるのかを確認します。
ざっくり結果から
まずは結果なんですけど。
チョー微妙な結果になりました。(むしろ失敗??)
それでも読んでみようという勇気のある方、この先をお読みください(笑)
実践
データ
前回の記事にも記載しましたが、データは以下のものを使っています。

Word2Vec
これも、前回の記事に記載していますが、概要の文章をWord2Vecを用いてベクトルにしています。
しかし、ここで求めたベクトルは概要の文章毎に次元数が異なります。
このため、ベクトル間のユークリッド距離が求められなかったのでWord2Vecを用いて作成したベクトル間で似たベクトルはコサイン類似度を用います。
コサイン類似度とは、
- 2つのベクトルが「どのくらい似ているか」という類似性を表す尺度のこと
- 値の範囲は-1 ~ 1
- 1→「0度で、同じ向きのベクトル=完全に似ている」0→「独立/直交した向きのベクトル=似ている/いない、のどちらにも無関係」-1→「反対向きのベクトル=完全に似ていない」ということ
- 要は1に近い方が似ているベクトルということ
pythonコード
コサイン類似度を求めるコードは以下のようになります。
# 「アバター」のベクトルを求める
movie_word2vec_df['cluster_label'] = labels
avater_df = movie_word2vec_df[movie_word2vec_df['title'] == "Avatar"]
avater_vectore = movie_word2vec_df[movie_word2vec_df['title'] == "Avatar"]['sentence_vectors'].values
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
target_label = 16 # 対象のクラスタのラベル
filtered_df = movie_word2vec_df[movie_word2vec_df['cluster_label'] == target_label]
movie_populer_df = filtered_df[filtered_df['popularity'] >= 80]
def get_similarity(x, original_vec):
x_array = np.array(x)
# コサイン類似度を計算
return cosine_similarity(x_array.reshape(1, -1), original_vec[0].reshape(1, -1))
movie_populer_df['similarity'] = movie_populer_df['sentence_vectors'].apply(get_similarity, original_vec=avater_vectore)
sorted_df = movie_populer_df.sort_values('similarity')結果
類似度1位:「インセプション」(Inception)
類似度:0.99989927

類似度2位:「マレフィセント」(Maleficent)
類似度:0.99981683

類似度3位:「ターミネーター:新起動/ジェニシス」(Terminator Genisys)
類似度:0.9997823

類似度4位:「ヒックとドラゴン2」(How to Train Your Dragon 2)
類似度:0.99976265

類似度5位:「アベンジャーズ」(The Avengers)
類似度:0.99969876

1位が「インセプション」は疑問なところですね。
4位の「ヒックとドラゴン2」はめっちゃわかります。
どれも0.99以上なのでほぼ似ているってことなんですよね。
3次元空間の距離を求める
次に3次元です。
3次元ベクトルはもう求めた前提で話を進めます。(カラム名や変数名は前回の記事と同じものです)
コサイン類似度とユークリッド距離で
コサイン類似度(結果)
コサイン類似度のコードは上記と同じなので割愛します。
結果は以下のようになりました。
類似度1位:「マレフィセント」(Maleficent)
類似度:0.9673
類似度2位:「アベンジャーズ」(The Avengers)
類似度:0.9499
類似度3位:「ターミネーター:新起動/ジェニシス」(Terminator Genisys)
類似度:0.9385
類似度4位:「ヒックとドラゴン2」(How to Train Your Dragon 2)
類似度:0.7600
類似度5位:「インセプション」(Inception)
類似度:0.6412
Word2Vecの時と作品は同じですが、順位が変わりました。
「マレフィセント」と「アベンジャーズ」と「ターミネーター:新起動/ジェニシス」が強いですね。
Word2Vecの時と同じく0.9越えです。
ただやはり、この3つ映画は決して「アバター」と類似しているとは思えません。
ユークリッド距離(pythonコード)
次にユークリッド距離です。
pythonコードは以下のようになります。(4行目は今回はアバターのWord2Vecで分類されたラベルが45なので、45です。)
(また、基準となるavater_vectoreを用意していますが、avater_vectoreの求めるコードは上記で記載済みです。)
import numpy as np
movie_word2vec_df['cluster_label'] = labels
target_label = 45 # 表示させたいクラスタのラベル
filtered_df = movie_word2vec_df[movie_word2vec_df['cluster_label'] == target_label]
movie_populer_df = filtered_df[filtered_df['popularity'] >= 80] # 知名度がある程度ある映画に絞る
def get_distance(x, original_vec):
return np.linalg.norm(np.array(x) - np.array(original_vec[0])) # ベクトル間の距離をもとめる
movie_populer_df['distance'] = movie_populer_df['combined_vectore'].apply(get_distance, original_vec=avater_vectore)
sorted_df = movie_populer_df.sort_values('distance')ユークリッド距離(結果)
結果は以下のようになりました。
k-means距離でベスト5を求める
1位:「ピクセル」(Pixels)
「アバター」との距離:39.01

2位:「ダークナイト ライジング」(The Dark Knight Rises)
「アバター」との距離:42.54

3位:「バットマン vs スーパーマン ジャスティスの誕生」(Batman v Superman: Dawn of Justice)
「アバター」との距離:54.09

4位:「ロード・オブ・ザ・リング/二つの塔」(The Lord of the Rings: The Two Towers)
「アバター」との距離:54.09

…
1位が「ピクセル」は全然系統違うやん。
そして気づいている方多いと思いますが、ベスト5位を表示すると言いながら4位までしか映画が載っていません。
要因としては以下の2つです。
- 分類を分け過ぎた
- ポピュラリティで絞ると全然映画が無い
✅分類を分け過ぎた
分類を多くすれば精度が上がると思いましたが、そもそも分類一つあたりの映画数が少なくなってしまったことが原因の一つ目です。(距離で近い映画を求めるなら前回の20個の分類でも良かったかもしれません)
✅ポピュラリティで絞ると全然映画が無い
今回使用したデータセットはポピュラリティ(popularity)という指標があるのですが、まあ知名度ですよね。
正直これ80以下だと本当に知らない映画がポンポン出てきます。
おそらく日本公開されていない作品もあります。
で、このポピュラリティの分布なのですが、以下のようになっています。
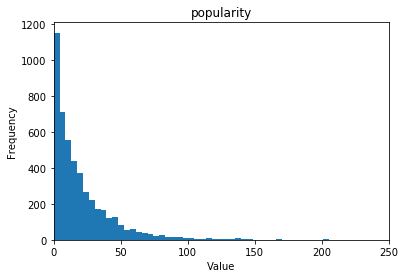
そうです、ほとんど50以下なんですよ。
ほとんど知らない映画ばっかなんすよね…。
まとめ
今回は改良を試みるということで分類の数を20から50に増やしてみました。
そして距離が近い方が似ている映画になるのかを確認しました。
結果はビミョーでした。
映画の概要文の長さじゃ短すぎるのかな…。
あと、ポピュラリティがそれなりに高い映画のデータ数が少ないのも問題でした。
ちょっとデータを変えてまたチャレンジしてみます。

