僕はDBをきちんと設計していませんでした。
データ自体は複雑なもの
今回は現在個人開発しているサービスのDBのデータ部分をきちんと論理設計から行いましたので、そのことについてまとめておきます。
今回は正規化を行い、ER図まで落とし込みました。
「達人に学ぶDB設計 徹底指南書」を参考にしています。
論理設計
論理設計は以下のステップで行います。
- エンティティの抽出
- エンティティの定義
- 正規化
- ER図の作成
ざっと説明すると、
エンティティは現実世界にあるデータの集合体を指していて、例えば「顧客」とか「店舗」とかです。
システムにはどのようなエンティティ(データ)が必要になるかを抽出するのが1つ目のステップです。
エンティティを抽出したら、各エンティティがどのようなデータを保持するのかを決めます。
これが2つ目のステップ「エンティティの定義」です。
エンティティ(テーブル)に関して、整理する作業がステップ3「正規化」です。
最後のステップ4でエンティティの見取り図として、エンティティ同士の関係を表すER図というものを作成します。
今回は扱うデータは決めているので、今回することは「正規化」と「ER図」の作成です。
また、正規化は基本的に第3正規化まで行うのですが、今回は第1正規化で正規化ができてしまったので、第1正規化まで。
正規化

正規化をしていきます。
まずは例を交えつつ、そもそも第1正規化とは何なのか、そして、第2正規化と第3正規化もどんなものか見ます。
そして、今回は桜の情報が入っている、sakura tableを用いて実施していきます。
第1正規化
第1正規化とは、データベース内のテーブルが「各列に単一の値のみを持つ」というルールを守る状態にすることです。
テーブル内のすべての列(フィールド)は単一の値で構成される必要があり、重複する列や複数の値を持つ列を持つことはできません。
また、データはリストや配列のような形式で格納されてはいけません。
例えば、以下のような「注文」テーブルがあったとします。(主キーに赤いアンダーラインを付けています)
| OrderID | Customer | Products | Total |
|---|---|---|---|
| 1 | John Doe | Product A, Product B | $50 |
| 2 | Jane Smith | Product C | $20 |
| 3 | Alice Lee | Product D, Product E | $70 |
これは、1つの注文で複数の商品(Products)が含まれているため、このテーブルは第1正規化Fに違反しています。
このテーブルを第1正規化するには、1つのセルに1つの値しか入れないようにテーブルを分割します。
各注文に対して、商品ごとに行を分けます。
「注文」テーブルと「注文詳細」テーブルに分けました。(主キーは赤いアンダーライン、外部キーは青文字にしています。)
✅「注文」テーブル
| OrderID | Customer | Total |
|---|---|---|
| 1 | John Doe | 50 |
| 2 | Jane Smith | 20 |
| 3 | Alice Lee | 70 |
✅「注文詳細」テーブル
| OrderID | Product | Price |
|---|---|---|
| 1 | Product A | 25 |
| 1 | Product B | 25 |
| 2 | Product C | 20 |
| 3 | Product D | 35 |
| 3 | Product E | 35 |
これで、第1正規化が完了です。
第2正規化
次に第2正規化とはどんなものかを見ていきます。
第2正規化を満たしている状態とは以下の状態を示します。
- 第1正規化を満たしていること
- 部分関数従属の排除ができていること
部分関数従属というのは、ということを説明する前に、そもそも関数従属性とはというところから書きます。
関数従属性とはある値xが1つ決まればyが1つに決まる性質を指します。
y = x + 1のようなものですね。
で、部分関数従属性は
「複数列からなる主キーの一部の列に対して従属する列がある状態」
を意味します。
この説明だけだとまだ分かりにくいので、例を示します。
例えば、以下の例では、StudentIDとCourseIDが主キーになっています。
しかし、良く見てみると、
✅クラスコーステーブル(第1正規化済み):
| StudentID | CourseID | CourseName | Instructor | InstructorPhone |
|---|---|---|---|---|
| 1 | 101 | Math | Smith | 555-1234 |
| 1 | 102 | Science | Johnson | 555-5678 |
| 2 | 101 | Math | Smith | 555-1234 |
| 2 | 103 | History | Lee | 555-9876 |
複合キーは「StudentID」と「CourseID」であり、テーブルの一意な行を特定するためにこの2つの値が必要になります。
上記で、部分関数従属性は「複数列からなる主キーの一部の列に対して従属する列がある状態」と書きました。
複数列からなる主キーは「StudentID」と「CourseID」です。
ここで、「CourseName」、「Instructor」、「InstructorPhone」は「CourseID」に依存しています。
「CourseID」が決まれば、この3つは一意に決まるからです。
「CourseID」には従属している状態です。
しかし、「StudentID」には依存していません。
これが、一部の列に対して従属する列がある状態です。
この部分関数従属性を無くすようにします。
具体的には、部分従属しているカラムを別のテーブルに分割します→「CourseID」のみ依存しているカラムを別のテーブル(今回はCourseInfo テーブル)に移動します。(主キーは赤いアンダーライン、外部キーは青文字にしています。)
✅StudentCourse テーブル
| StudentID | CourseID |
|---|---|
| 1 | 101 |
| 1 | 102 |
| 2 | 101 |
| 2 | 103 |
✅CourseInfo テーブル
| CourseID | CourseName | Instructor | InstructorPhone |
|---|---|---|---|
| 101 | Math | Smith | 555-1234 |
| 102 | Science | Johnson | 555-5678 |
| 103 | History | Lee | 555-9876 |
これで各カラムが完全に主キー(または複合キー)に依存するようになりました。
第3正規化
非キー属性(キーではないカラム)が他の非キー属性に依存しないようにテーブルを分割します(これを「推移的関数従属の排除」と言います)
第2正規化した「CourseInfo」 テーブルを見てみてみます。(上記のものを再掲)
| CourseID | CourseName | Instructor | InstructorPhone |
|---|---|---|---|
| 101 | Math | Smith | 555-1234 |
| 102 | Science | Johnson | 555-5678 |
| 103 | History | Lee | 555-9876 |
講師の情報(Instructor と InstructorPhone)が入っていますが、これらは CourseID ではなく、Instructor に依存しています。
これを第3正規化するために、講師に関する情報を別のテーブルに分けます。
✅StudentCourse テーブル(そのまま変更なし)
| StudentID | CourseID |
|---|---|
| 1 | 101 |
| 1 | 102 |
| 2 | 101 |
| 2 | 103 |
✅CourseInfo テーブル
| CourseID | CourseName | InstructorID |
|---|---|---|
| 101 | Math | 1 |
| 102 | Science | 2 |
| 103 | History | 3 |
✅InstructorInfo テーブル
| InstructorID | Instructor | InstructorPhone |
|---|---|---|
| 1 | Smith | 555-1234 |
| 2 | Johnson | 555-5678 |
| 3 | Lee | 555-9876 |
これにより、InstructorPhone が InstructorID にのみ依存し、第3正規化が完了しました(推移的関数従属が排除されました)
今回の場合
今回扱うテーブルは以下のようなテーブルです。
桜の情報が載っているテーブルで、season_listカラムとして見ごろの月のデータが入っています。
| id | spot_name | season_list | etc… |
|---|---|---|---|
| 1 | Spot A | 3,4 | … |
| 2 | Spot B | 4,5 | … |
「3,4」、「4,5」というように、値が列に複数入っています。
これでは第1正規化に違反してしまっています。
なので、以下のように第1正規化を実施します。
sakura_table(元のテーブル、season_list カラムは削除)
| id | spot_name | … |
|---|---|---|
| 1 | Spot A | … |
| 2 | Spot B | … |
sakura_season_table(シーズンごとに分割した新しいテーブル)
| id | season |
|---|---|
| 1 | 3 |
| 1 | 4 |
| 2 | 4 |
| 2 | 5 |
今回の場合は第2正規化を満たしています。
しかし、第3正規化は満たしていませんので、第3正規化もする必要があります。
sakura_tableではidではなくspot_nameカラムに依存しているので、テーブルを分けます。
idとspot_nameをもとのsakura_tableに残して、残りを別のsakura_info_tableに移しました。
こんな感じ👇
sakura_table(元のテーブル、season_list カラムは削除)
| id | spot_name |
|---|---|
| 1 | Spot A |
| 2 | Spot B |
sakura_info_tableは以下。
| spot_name | sakura_genre | … |
|---|---|---|
| Spot A | ソメイヨシノ | … |
| Spot B | エドヒガンザクラ | … |
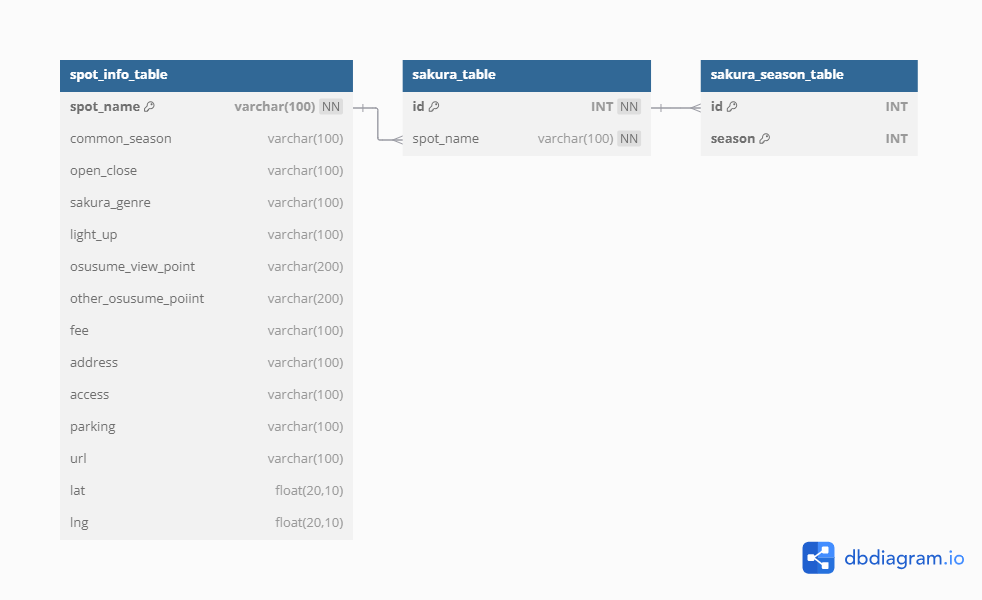
ER図
ER図とはデータベース設計界隈でデファクトスタンダードな設計図です。
今回はER図を作成するにあたって、以下のサイトを使用しました。

DDLから自動でER図を作成してくれます。
今回作成されたER図は以下です。