
はじめに
前回、天気と東京ディズニーランドの待ち時間どう関係しているのかをpythonを使って調べてみました。
今回は待ち時間を予測できるのかを試してみます。
タイトルにもあるように、LSTMよりランダムフォレストの方が上手くいきました。
では、どのような結果になったのか、具体的に見ていきましょう。
学習
LSTM(データ)
そもそもデータ量が少ないので、nanの値をdropすると学習できたもんじゃない。
だからnanを0にして、試してみました。
LSTMについては過去に天気の記事をだしているので、そちらで確認いただければと思います。
今回も過去の天気の記事と同様のpythonコードを書いています。
天気の情報と、ディズニーランドの待ち時間のデータを用いて実施しました。
データに関しては前回の以下の記事に記載しているので、良ければ読んでみてください。
今回のLSTMでは、「美女と野獣 魔法のものがたり」の待ち時間を予測してみました。
LSTM実行結果
結果として、損失関数は減少してくれました。
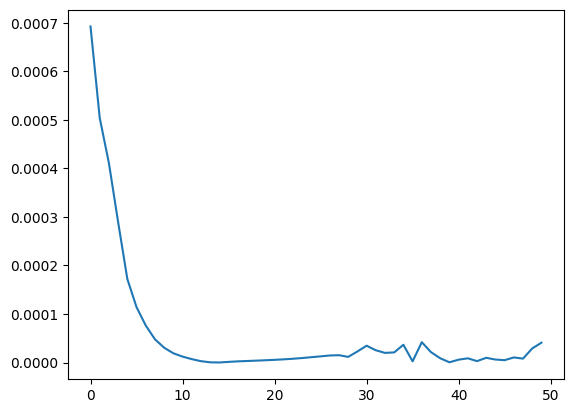
しかし、実際にテストデータの予測をしてみると芳しくない結果となりました。
以下が、テストデータ部分の予測と実際の値の比較のグラフになります。
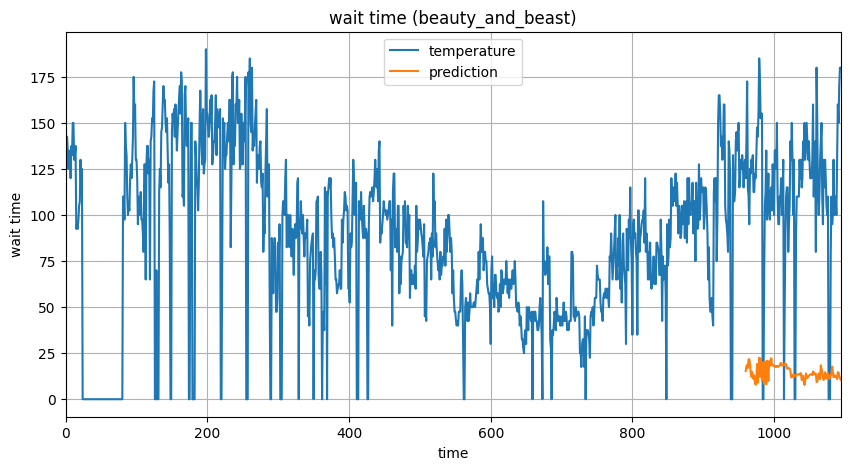
全然、予測できてないやないか!!
そもそもディープラーニングにしてはデータが少ないというのもありますし、時間軸が果たして関係あるのかというのもあります。
つまり、天気は季節の影響があるため、ある程度規則性があります。
しかし、前回の記事にもあったように天気が待ち時間が影響しているのって気温がそこそこ相関係数があるだけなんですよね。
そこで、一旦、時間軸で考えずに予測してみようと思いました。
今回はランダムフォレストによる待ち時間の予測を実施してみます。
ランダムフォレスト
ランダムフォレストでも扱うデータにnanがあってはいけないのでdropします。
ただ、全てドロップするとデータが無くなるので、100件以上あるカラムは今回の学習から外します。
以下が今回の学習では扱わないカラムです。(カラムに関しては前回の記事に記載■)
big_thunder_mountain 384
honey_hunt 360
haunted_mansion 177
buzz_lightyear 225
plaza_bandstand 1095
hokusai 330
crystal_palace 390「美女と野獣 魔法のものがたり」の待ち時間に対してランダムフォレストを実施してみます。
参考までにコードを記載しておきます👇
from sklearn.model_selection import train_test_split
from sklearn import linear_model
import numpy as np
from sklearn.metrics import mean_squared_error as MSE
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
y_data = shaped_df['beauty_and_beast']
train_data = shaped_df.drop(['beauty_and_beast'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(train_data, y_data, test_size=0.2, random_state=1, shuffle=True)
frf = RandomForestRegressor()
frf.fit(X_train, y_train)
y_pred_train = frf.predict(X_train)
rsme_train = np.sqrt(MSE(y_train, y_pred_train))
print('学習データに対する回帰への評価(RMSEの値):', rsme_train)
print('学習データに対する決定係数:', frf.score(X_train,y_train))
y_pred_test = frf.predict(X_test)
rsme_test = np.sqrt(MSE(y_test, y_pred_test))
print('テストデータに対する回帰への評価(RMSEの値):', rsme_test)
print('テストデータに対する決定係数:', frf.score(X_test,y_test))結果は以下のようになりました。
学習データに対する回帰への評価(RMSEの値): 11.687108403918833
学習データに対する決定係数: 0.9264417723792526
テストデータに対する回帰への評価(RMSEの値): 28.82341035295789
テストデータに対する決定係数: 0.5159116754158697テストデータに関する相関係数が高くありません。
いい学習ができていないようです。。。
が、グラフを一応確認しておきましょう。
テストデータの実際の値と予測してみた値とのグラフです。
from matplotlib import pyplot as plt
plt.figure(figsize=(5, 5))
plt.scatter(y_test, y_pred_test)
plt.xlabel('real time')
plt.ylabel('prediction time')
plt.title("beauty_and_beast wait time test data, real vs predict")
plt.show()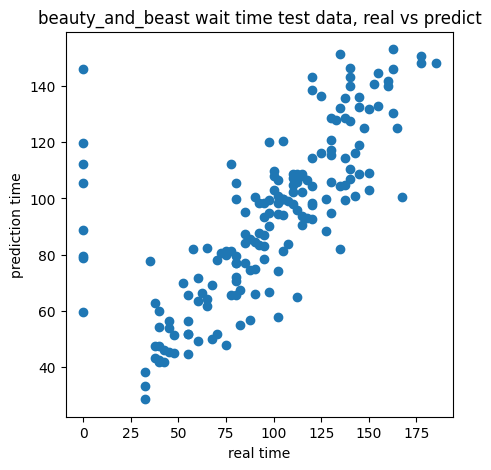
予測したけど、待ち時間が0になっているものがありますね。(予測では120hなどだけど、実際は0hのもの)
そもそも実際の値で0のとこは省いて学習させた方がいいのかもしれないです。
重要度
次に、この結果に対する重要度を求めてみます。
重要度は予測に対して各パラメータがどれくらい影響しているかを表します。
重要度が高いパラメータベスト10で求めてみます。
happy_ride : 0.2620105618004672
monsters_inc : 0.22213338366991825
気温(℃) : 0.10782672807979697
splash_mountain : 0.07720589000552758
star_tuors : 0.05730575632637506
風速(m/s) : 0.039561718244969526
minnie_style_studio : 0.03746684267733286
woodchuck_donald : 0.03460663616794487
mickey_house : 0.01885204198823972
woodchuck_daisy : 0.01824289053882598
「happy_ride」は「ベイマックス ハッピーライド」の待ち時間、
「monsters_inc」は「モンスターズ インク」の待ち時間
の値なので、「美女と野獣 魔法のものがたり」は「ベイマックス ハッピーライド」の待ち時間と「モンスターズ インク」の待ち時間に特に影響することがわかります。
また、それなりに気温にも影響していますね。
次に、重要度が低いパラメータベスト10(ワースト10かもね)で求めてみます。
polynesian_terrace : 0.0
diamond_horseshoe : 0.0
降雪(cm) : 0.0
風向_西 : 0.0
風向_静穏 : 0.0
風向_西南西 : 0.0003027952012530425
風向_南西 : 0.0003988706206462413
holiday_flag_False : 0.0004455540352924018
風向_東北東 : 0.0006922995682657953
風向_東南東 : 0.0007281069276035417
風向きはほとんど関係ないようですね。
諸葛孔明みたいに風向きを見て戦略を練ることは難しそうです。
また、意外なのは「holiday_flag_False」が影響がないことです。
「holiday_flag_False」は休日でない日を表します。
つまり、休日で無い日は待ち時間に影響がほとんどない事を示しています。
最後に
今回はLSTMとランダムフォレストで「美女と野獣 魔法のものがたり」の待ち時間を予測しました。
ランダムフォレストの方がうまく予測できました。
ただ、まだ精度は高いとは言えません。
重要度も求めました。
最も影響しているのは「ベイマックス ハッピーライド」の待ち時間。
そして、「モンスターズ インク」の待ち時間、「気温」と続きます。
「ベイマックス ハッピーライド」が待ち時間が長い場合は、「美女と野獣 魔法のものがたり」に並ぶ選択をしない方がいい事になります。
そして、問題はディズニーランド内の待ち時間はあくまでその時点の値なので、前日以前に予測ができません。
できれば、前日に予測されている天気などの情報から予測したいところです。

