
はじめに
今回はPyTorchと機械学習の勉強のためにLSTMのコードを実際に作ってみました。
僕は
✅PyTorch
✅LSTM
✅Google Colaboratory
に関しては初心者なので、勉強の復習の意味を込めてこの記事を記載します。
使用したデータは気象庁の1時間ごとのデータで1年分用意しています。

多分、機械学習に際してデータ量は足りないかもしれないですが、このデータで試してみました。
今回参考にしたサイトは以下です。 とても素晴らしい記事でした。

結構コードの部分は参照させていただきました。
RNNとLSTM
LSTMの前にRNNも初心者なので、RNNについても記載しておきます。
- RNN(リカレントニューラルネットワーク)は、「時系列データ」や「順序を持つデータ」を扱うために作られた特殊なニューラルネットワーク
- 「過去の情報を利用して現在を理解する」仕組みを持っていて、隠れ層の情報が次の時間のステップにも引き継がれる
- RNNの弱点としては以下が挙げられる
- 遠い過去の情報を記憶することは難しい
- 勾配消失(勾配が小さい状態で計算を繰り返していくと、勾配がほぼ0になってしまう現象のこと)という問題が起きやすい
LSTM(Long Short-Term Memory)は上記のRNNの弱点を解消するために登場しました。
LSTMは「忘れる」「記憶する」を制御する仕組みを持ち、長期的な依存関係を扱いやすいです。
具体的には以下の3つの仕組みをもっています。
- 忘却ゲート(Forget Gate)
- 過去の情報の内、どれを捨てるかを決める
- 入力ゲート(Input Gate)
- 新しい情報の中から、どれを記憶するかを決める
- 出力ゲート(Output Gate)
- 現時点で必要な情報を、外部に出力する
実装
では、実際のpythonで実装していきます。
実装環境としてはGoogle Google Colaboratoryを使用しています。
CSVからdataframeを作成するところまで
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
%matplotlib inline
device = 'cuda' if torch.cuda.is_available else 'cpu'ドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')csvからdataframeを作成します。
import pandas as pd
import os
import codecs
folder_path = "drive/MyDrive/Colab Notebooks/Data/weather"
# フォルダ内のすべてのCSVファイルを取得
csv_files = [f for f in os.listdir(folder_path) if f.endswith('.csv')]
# 空のリストを用意して、各CSVファイルを格納
dataframes = []
for file in csv_files:
file_path = os.path.join(folder_path, file)
with codecs.open(file_path, "r", "Shift-JIS", "ignore") as file:
df = pd.read_table(file, delimiter=",")
dataframes.append(df)
# 複数のDataFrameを1つに結合
weather_dataframe = pd.concat(dataframes, ignore_index=True)
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
weather_dataframe['年月日時'] = pd.to_datetime(weather_dataframe['年月日時'])
weather_dataframe = weather_dataframe.sort_values(by='年月日時').reset_index(drop=True)
# weather_dataframe['Timestamp'] = weather_dataframe['年月日時'].apply(lambda x: x.timestamp())
# 必要なカラムを選択
weather_dataframe = weather_dataframe[['年月日時', '気温(℃)', '降水量(mm)', '降雪(cm)', '日照時間(時間)', '風速(m/s)', '風向']]
weather_dataframe = pd.get_dummies(weather_dataframe, columns=['風向'], prefix='風向')
weather_dataframe['気温(℃)'] = weather_dataframe['気温(℃)'].fillna(0)
weather_dataframe['降雪(cm)'] = weather_dataframe['降雪(cm)'].fillna(0)
weather_dataframe['日照時間(時間)'] = weather_dataframe['日照時間(時間)'].fillna(0)
weather_dataframe['風速(m/s)'] = weather_dataframe['風速(m/s)'].fillna(0)実際にグラフを見てみましょう。
plt.plot(weather_dataframe['年月日時'], weather_dataframe['気温(℃)'])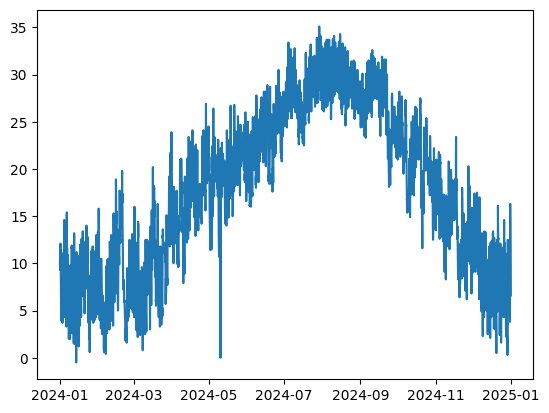
2024年の一年間の気温が確認できました。
データの確認をします。
print(weather_dataframe.shape)
print(weather_dataframe.tail(5))出力は以下のようになります。
(8784, 23)
年月日時 気温(℃) 降水量(mm) 降雪(cm) 日照時間(時間) 風速(m/s) 風向_北 \
8779 2024-12-31 20:00:00 8.9 0.0 0.0 0.0 5.8 False
8780 2024-12-31 21:00:00 8.1 0.0 0.0 0.0 4.4 False
8781 2024-12-31 22:00:00 7.4 0.0 0.0 0.0 5.7 False
8782 2024-12-31 23:00:00 6.8 0.0 0.0 0.0 4.9 False
8783 2025-01-01 00:00:00 6.6 0.0 0.0 0.0 4.2 False
風向_北北東 風向_北北西 風向_北東 ... 風向_南南西 風向_南東 風向_南西 風向_東 風向_東北東 風向_東南東 \
8779 False True False ... False False False False False False
8780 False True False ... False False False False False False
8781 False True False ... False False False False False False
8782 False True False ... False False False False False False
8783 False True False ... False False False False False False
風向_西 風向_西北西 風向_西南西 風向_静穏
8779 False False False False
8780 False False False False
8781 False False False False
8782 False False False False
8783 False False False False
[5 rows x 23 columns]そんなにデータがありません。
一年間の気温と降水量と風速のグラフを表示してみます。
fig, (axT, axP, axW) = plt.subplots(ncols=3, figsize=(20,5))
axT.plot(feature_data['気温(℃)'], linewidth=2)
axT.set_title('temperature')
axT.set_xlabel('date')
axT.set_ylabel('temperature(C)')
axT.grid(True)
axP.plot(feature_data['降水量(mm)'], linewidth=2)
axP.set_title('precipitation')
axP.set_xlabel('date')
axP.set_ylabel('precipitation(mm)')
axP.grid(True)
axW.plot(feature_data['風速(m/s)'], linewidth=2)
axW.set_title('wind')
axW.set_xlabel('date')
axW.set_ylabel('wind(m/s)')
axW.grid(True)
fig.show()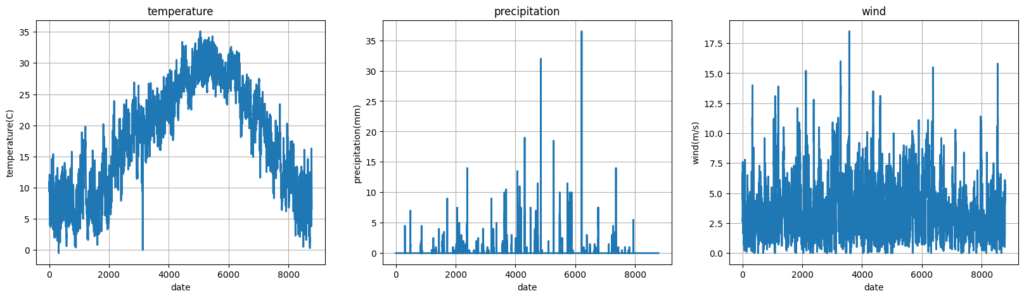
学習前の準備まで
テストデータは後半の1757時間分(全体の2割)にします。
# 後半1757時間分(全体の2割)をテストデータにする
test_data_size = 1757
train_data = feature_data[:-test_data_size]
test_data = feature_data[-test_data_size:]正規化を行います。
# データセットの正規化を行う。最小値0と最大値1の範囲で行う。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
train_data_normalized = scaler.fit_transform(train_data)ここで正規化をするのは、数値データを 0 から 1 の範囲 にスケーリングすることが目的です。
例えば、気温(℃) の値が -10 から 40 までの範囲、降水量(mm) の値が 0 から 200 の範囲だとします。これらの特徴量が異なるスケールにあると、モデルがそれぞれに異なる重要性を持って学習しがちですが、正規化をすることにより、例えば、気温(℃) が -10 の場合、0 に近い値に変換され、降水量(mm) が 200 の場合、1 に近い値に変換されます。これにより、モデルが学習する際にすべての特徴量が等しいスケールで処理されるようになります。
PyTorchを使ってTensor型に変換します。
train_data_normalized = torch.FloatTensor(train_data_normalized)シーケンスに沿ったデータを作成する関数を定義します。
# シーケンスに沿ったデータを作成する関数
def make_sequence_data(input_data, num_sequence):
data = []
num_data = len(input_data)
# 全体からシーケンス分引いた数までループする
for i in range(num_data - num_sequence):
# 1個ずらして、シーケンス分のデータを取得していく
seq_data = input_data[i:i+num_sequence]
target_data = input_data[:,0][i+num_sequence:i+num_sequence+1]
data.append((seq_data, target_data))
return dataこの関数はLSTMに入力するためのシーケンスデータを作成するための関数です。
時系列データをスライドしながら「入力データ」と「ターゲットデータ」を作ることを目的にしています。
例えば以下のように入力された値に対して一つずつずらしていくイメージです。
例:
input_data = [1, 2, 3, 4, 5, 6]
num_sequence = 3
i = 0 → seq_data = [1, 2, 3]
i = 1 → seq_data = [2, 3, 4]今回はシーケンス長は12時間としています。
train_seq_dataが最初のデータを1個ずらしてシーケンス分のデータとして求めます
# シーケンス長は12時間とする
seq_length = 12
# train_seq_data=最初のデータを1個ずらしてシーケンス分のデータ(時系列の学習データ群)、train_target=train_seq_dataの次のデータ(ラベルデータ)
train_seq_data = make_sequence_data(train_data_normalized, seq_length)学習
LSTMの関数を用意します。
class LSTM(nn.Module):
def __init__(self, input_size=3, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_layer_size, batch_first=True)
self.linear = nn.Linear(in_features=hidden_layer_size, out_features=output_size)
def forward(self, x):
lstm_out, (hn, cn) = self.lstm(x, None)
# Linearのinputは(N,∗,in_features)にする
# lstm_out(batch_size, seq_len, hidden_layer_size)のseq_len方向の最後の値をLinearに入力する
prediction = self.linear(lstm_out[:, -1, :])
return predictionモデルとして定義します。
model = LSTM()
model.to(device)ここで、
RuntimeError: Found no NVIDIA driver on your system. Please check that you have an NVIDIA GPU and installed a driver from ~~
というエラーが出る場合は
このコードの前に以下をする。CPUを使うことになるけどね。。。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}") # 使用しているデバイスを確認損失関数と最適化関数を定義します。
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)学習します。エポック数は50です。
epochs = 50
losses = []
for i in range(epochs):
for seq, labels in train_seq_data:
seq, labels = torch.unsqueeze(seq, 0), torch.unsqueeze(labels, 0)
seq, labels = seq.to(device), labels.to(device)
optimizer.zero_grad()
y_pred = model(seq)
single_loss = criterion(y_pred, labels)
single_loss.backward()
optimizer.step()
losses.append(single_loss.item())
print(f'epoch: {i}, loss : {single_loss.item()}')学習の結果を確認するために損失関数をプロットしてみます。
plt.plot(losses)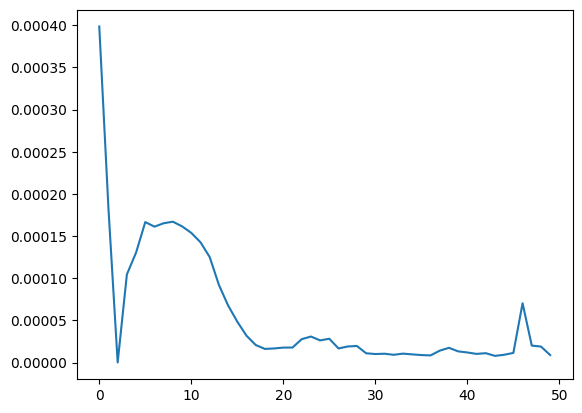
損失関数が減っていることが確認できます。
最後に
学習まで完了しました。
次回の予測に続きます。
結論、
の記事が素晴らしかったです。

