
ふと、食べログをスクレイピングしようと思った。
理由はいくつかあった。
評価値と値段の相関性を知りたかったり、低い金額でもおいしいお店を見つけたかったり、身内でおいしいお店を紹介したかったり。
とりあえず、あの巨大なデータを一つ一つ見るのではなく、鳥瞰して見たかったのだ。
1杯のコーヒーを淹れ、コーヒーの入ったコップを机に置きパソコンへと向かう。
pythonプログラミングを書いていく。
まずはrobots.txtのチェック

まず、スクレイピングするにあたってしてはいけない事を確認する。
robots.txtのチェックである。
robots.txtについてはこちらの記事にも記載した。
そのために食べログのrobots.txt(こちらのURL)にアクセスする。
すると以下のようなものが表示される(2022年6月現在)
User-agent: *
Disallow: /ad_mobile/
Disallow: /rvwr/*/visitdtl/
Disallow: /yoyaku/tabelog_booking/
Disallow: /blog/to_blog
Disallow: /btb/
User-agent: Baiduspider
Crawl-delay: 5
User-agent: BaiduMobaider
Crawl-delay: 10
User-agent: BaiduImagespider
Crawl-delay: 10
User-agent: bingbot
Crawl-delay: 5
User-agent: psbot
Disallow: /
User-agent: BecomeBot
Disallow: /
User-agent: Teoma
Disallow: /
User-agent: Ask Jeeves
Disallow: /
User-agent: ListRan
Disallow: /
まず以下の部分
User-agent: *
Disallow: /ad_mobile/
Disallow: /rvwr/*/visitdtl/
Disallow: /yoyaku/tabelog_booking/
Disallow: /blog/to_blog
Disallow: /btb/ここは全てのユーザーエージェント(User-agent: *)に対してページへのスクレイピングを禁止するというもの。
例えば予約の履歴ページは「https://ssl.tabelog.com/yoyaku/tabelog_booking/send_remind/」というURLなのでスクレイピングでのアクセスはダメってこと。
後は
User-agent: Baiduspider
Crawl-delay: 5のところはBaiduspiderというユーザーエージェントは5秒間隔でクローリングするように書いてある。
ちなみにBaiduspiderは中国の検索サイト「百度」のために、ウェブサイトの情報を収集するクローラーの事なので今回のスクレイピングには特に関係ない。
他にもbingbotはMicrosoftがBingにて提供する、ウェブ上からドキュメントを収集するクローラーだったりするので他のユーザーエージェントについて興味のある方は調べてみるのもいいかも。
ただ今回のスクレイピングは全てのユーザーエージェント(User-agent: *)に対してのところを見るのでその対象のURLに注意してスクレイピングをしていくとする。
収集について(エリアを分けて収集する)

スクレイピングするにあたり、対象のページについて把握しておく必要がある。
今回はお店の情報の内、点数と金額を集めてみようと思いますので、どのように集めようか考える。
例えば、東京だけでもお店の数は130,000件以上ある。(2022年6月現在)(東京は他の都道府県に比べて突出して多いですが。。。)
そして食べログは60ページまでしか表示できないようなので、1200件までしか情報が取得できない。
ですのでエリアごとに分けて情報を収集したいと思う。
例えば東京の銀座エリアに絞れば2500件ほどに減る。(それでも1200件までしか情報が無いのですべては集められません。。)
その中でもランキングで評価値が高い順にして評価の高いお店を逃さないようにする。
今回はできるだけお店を集めることにしてすべて集めきることを目的にしないようにする。
全てのお店を集めきろうとするとそれが目的になってしまうので、目的が変わらないように気を付けて進めていくのがコツ。
今回はランキングのページの1ページ分の値をとる。
何かを開発するときは小さなステップを踏んで作っていくのがいい。最初からすごいコードを書こうとするとたいてい挫折する。
なので今回は1ページ分。
まずは1つのエリアの1ページで値を収集する

お店の項目を取得
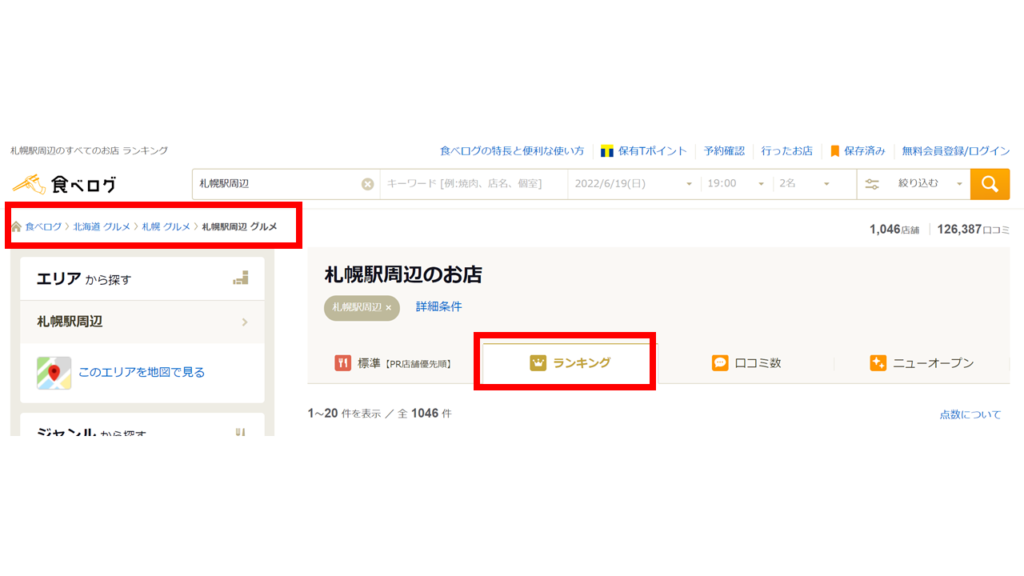
今回は北海道の札幌駅周辺のお店に絞る。
リンクとしては「https://tabelog.com/hokkaido/A0101/A010101/rstLst/1/?Srt=D&SrtT=rt&sort_mode=1」。
階層としては
「食べログ→北海道グルメ→札幌グルメ→札幌駅周辺グルメ」
となる。以下の画像の赤枠のところ。ランキングの上位から集めるとする。
さて、もうコードを書いていく。
言語はpython。
まず対象のページのランキングのところにある各お店の項目の領域を取得するコードは以下。
import requests
from bs4 import BeautifulSoup
taberogu_url = "https://tabelog.com/"
todoufuken_item = "hokkaido/A0101"
erea_item = "/A010101"
taberogu_detail_url = taberogu_url + todoufuken_item + erea_item + "/rstLst/1/?Srt=D&SrtT=rt&sort_mode=1"
response = requests.get(taberogu_detail_url)
soup = BeautifulSoup(response.text, 'html.parser')
ret = soup.find_all('div', {'class':'list-rst__rst-data'})URLを変数にしているのでわかりくいけど後で便利なのでそうしている。
以下のコードのところで対象のurlのページのhtml情報を取得している。
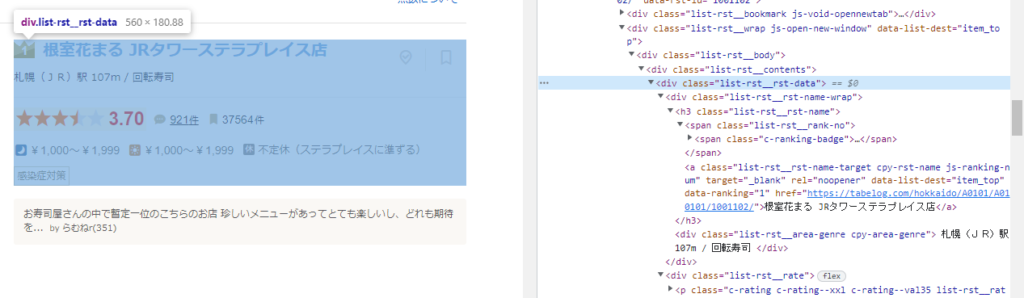
soup = BeautifulSoup(response.text, 'html.parser')そして、そのhtml情報の中からお店の項目の領域を取得しているコードの部分は以下。
ret = soup.find_all('div', {'class':'list-rst__rst-data'})以下の画像のように対象の部分はchromeブラウザで開いたサイトの画面を右クリック→検証で出すことのできるhtml情報の中から対象のところにマウスを持っていくとそれに連動してページの領域が青くなる。
それで上記のコードのところを知ることができる。
このコードでfind_allで値を取得している。
find_allは今回の場合だとdivでclassの値が「list-rst__rst-data」のものをすべて集める。
つまり、それら全てがリストとして保存される。(何言っている分からない方は軽くスルーして大丈夫です。後にまたこの事は出てくるのでそこで詳しく見ます。)
「list-rst__rst-data」のclassは上記の画像の青の部分であり、これが今回のページには20個ある。
つまり、リストには20個の「list-rst__rst-data」のclassのhtlm部分があるという事だ。
このリストに保存された20個のhtlmの値を一つ一つループで処理をしていく。
まずコードを載せておく。(下記に詳細な説明は載せてある。)
for ret_item in ret:
store_name = ret_item.find('a', {'class':'list-rst__rst-name-target cpy-rst-name js-ranking-num'}).get_text()
score = float(ret_item.find('span', {'class':'c-rating__val c-rating__val--strong list-rst__rating-val'}).get_text())
value = ret_item.find_all('span', {'class':'c-rating-v3__val'})
day_value = value[1].get_text()
night_value = value[0].get_text()
print("お店の名前:", store_name)
print("ランチ帯の価格:", day_value)
print("ディナー帯の価格:", night_value)
area_and_ganre = ret_item.find('div', {'class':'list-rst__area-genre cpy-area-genre'}).get_text()
print("ジャンルの抽出部分:", area_and_ganre)
ganre = area_and_ganre.split('/')
print("場所とジャンル:", ganre)
ganre_tags = ganre[1].split('、')
ganre_tags = [n.replace("\n","").replace(" ","") for n in ganre_tags]
print("ジャンルのタグ:", ganre_tags)
print("----------------------------")これを実行すると以下のようになる。
お店の名前: 鮨 田なべ
ランチ帯の価格: -
ディナー帯の価格: ¥15,000~¥19,999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 297m / 寿司
場所とジャンル: [' さっぽろ(札幌市営)駅 297m ', ' 寿司\n ']
ジャンルのタグ: ['寿司']
----------------------------
お店の名前: 味百仙
ランチ帯の価格: -
ディナー帯の価格: ¥5,000~¥5,999
ジャンルの抽出部分: 札幌(JR)駅 189m / 居酒屋、日本酒バー、魚介料理・海鮮料理
場所とジャンル: [' 札幌(JR)駅 189m ', ' 居酒屋、日本酒バー、魚介料理・海鮮料理\n ']
ジャンルのタグ: ['居酒屋', '日本酒バー', '魚介料理・海鮮料理']
----------------------------
お店の名前: カリーハウス コロンボ
ランチ帯の価格: ~¥999
ディナー帯の価格: ~¥999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 31m / カレーライス
場所とジャンル: [' さっぽろ(札幌市営)駅 31m ', ' カレーライス\n ']
ジャンルのタグ: ['カレーライス']
----------------------------
お店の名前: KINOTOYA BAKE JR札幌駅東口店
ランチ帯の価格: ~¥999
ディナー帯の価格: ~¥999
ジャンルの抽出部分: 札幌(JR)駅 41m / ケーキ、スイーツ(その他)
場所とジャンル: [' 札幌(JR)駅 41m ', ' ケーキ、スイーツ(その他)\n ']
ジャンルのタグ: ['ケーキ', 'スイーツ(その他)']
----------------------------
お店の名前: ぱん吉
ランチ帯の価格: ~¥999
ディナー帯の価格: ~¥999
ジャンルの抽出部分: 札幌(JR)駅 324m / パン、サンドイッチ、パン・サンドイッチ(その他)
場所とジャンル: [' 札幌(JR)駅 324m ', ' パン、サンドイッチ、パン・サンドイッチ(その他)\n ']
ジャンルのタグ: ['パン', 'サンドイッチ', 'パン・サンドイッチ(その他)']
----------------------------
お店の名前: 鉄板焼 やまなみ
ランチ帯の価格: ¥6,000~¥7,999
ディナー帯の価格: ¥15,000~¥19,999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 447m / 鉄板焼き、ステーキ
場所とジャンル: [' さっぽろ(札幌市営)駅 447m ', ' 鉄板焼き、ステーキ\n ']
ジャンルのタグ: ['鉄板焼き', 'ステーキ']
----------------------------
お店の名前: フレンチレストラン ミクニ サッポロ
ランチ帯の価格: ¥5,000~¥5,999
ディナー帯の価格: ¥10,000~¥14,999
ジャンルの抽出部分: 札幌(JR)駅 92m / フレンチ
場所とジャンル: [' 札幌(JR)駅 92m ', ' フレンチ\n ']
ジャンルのタグ: ['フレンチ']
----------------------------
お店の名前: ラーメン札幌一粒庵
ランチ帯の価格: ~¥999
ディナー帯の価格: ~¥999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 310m / ラーメン、餃子、薬膳
場所とジャンル: [' さっぽろ(札幌市営)駅 310m ', ' ラーメン、餃子、薬膳\n ']
ジャンルのタグ: ['ラーメン', '餃子', '薬膳']
----------------------------
お店の名前: 函館うに むらかみ 日本生命札幌ビル店
ランチ帯の価格: ¥1,000~¥1,999
ディナー帯の価格: ¥6,000~¥7,999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 134m / 魚介料理・海鮮料理、海鮮丼、懐石・会席料理
場所とジャンル: [' さっぽろ(札幌市営)駅 134m ', ' 魚介料理・海鮮料理、海鮮丼、懐石・会席料理\n ']
ジャンルのタグ: ['魚介料理・海鮮料理', '海鮮丼', '懐石・会席料理']
----------------------------
お店の名前: ユーヨーテラスサッポロ
ランチ帯の価格: ¥2,000~¥2,999
ディナー帯の価格: -
ジャンルの抽出部分: さっぽろ(札幌市営)駅 197m / バイキング、洋食、中華料理
場所とジャンル: [' さっぽろ(札幌市営)駅 197m ', ' バイキング、洋食、中華料理\n ']
ジャンルのタグ: ['バイキング', '洋食', '中華料理']
----------------------------
お店の名前: 根室花まる JRタワーステラプレイス店
ランチ帯の価格: ¥1,000~¥1,999
ディナー帯の価格: ¥1,000~¥1,999
ジャンルの抽出部分: 札幌(JR)駅 104m / 回転寿司
場所とジャンル: [' 札幌(JR)駅 104m ', ' 回転寿司\n ']
ジャンルのタグ: ['回転寿司']
----------------------------
お店の名前: スープカリー ヒリヒリ2号
ランチ帯の価格: ¥1,000~¥1,999
ディナー帯の価格: ¥1,000~¥1,999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 397m / スープカレー、カレー(その他)、ダイニングバー
場所とジャンル: [' さっぽろ(札幌市営)駅 397m ', ' スープカレー、カレー(その他)、ダイニングバー\n ']
ジャンルのタグ: ['スープカレー', 'カレー(その他)', 'ダイニングバー']
----------------------------
お店の名前: 175°DENO〜担担麺〜 札幌北口店
ランチ帯の価格: ~¥999
ディナー帯の価格: ~¥999
ジャンルの抽出部分: 札幌(JR)駅 126m / ラーメン、担々麺、居酒屋
場所とジャンル: [' 札幌(JR)駅 126m ', ' ラーメン、担々麺、居酒屋\n ']
ジャンルのタグ: ['ラーメン', '担々麺', '居酒屋']
----------------------------
お店の名前: スープカリー 奥芝商店 駅前創成寺
ランチ帯の価格: ¥1,000~¥1,999
ディナー帯の価格: ¥1,000~¥1,999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 316m / スープカレー、カレーライス、ハンバーグ
場所とジャンル: [' さっぽろ(札幌市営)駅 316m ', ' スープカレー、カレーライス、ハンバーグ\n ']
ジャンルのタグ: ['スープカレー', 'カレーライス', 'ハンバーグ']
----------------------------
お店の名前: カリーサボイ
ランチ帯の価格: ¥1,000~¥1,999
ディナー帯の価格: ¥1,000~¥1,999
ジャンルの抽出部分: 札幌(JR)駅 308m / スープカレー
場所とジャンル: [' 札幌(JR)駅 308m ', ' スープカレー\n ']
ジャンルのタグ: ['スープカレー']
----------------------------
お店の名前: ショコラティエ マサール パセオ店
ランチ帯の価格: ¥1,000~¥1,999
ディナー帯の価格: ¥1,000~¥1,999
ジャンルの抽出部分: 札幌(JR)駅 29m / チョコレート、ケーキ
場所とジャンル: [' 札幌(JR)駅 29m ', ' チョコレート、ケーキ\n ']
ジャンルのタグ: ['チョコレート', 'ケーキ']
----------------------------
お店の名前: ピカンティ 札幌駅前店
ランチ帯の価格: ¥1,000~¥1,999
ディナー帯の価格: ¥1,000~¥1,999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 403m / スープカレー
場所とジャンル: [' さっぽろ(札幌市営)駅 403m ', ' スープカレー\n ']
ジャンルのタグ: ['スープカレー']
----------------------------
お店の名前: 麺や ハレル家
ランチ帯の価格: ~¥999
ディナー帯の価格: ~¥999
ジャンルの抽出部分: 札幌(JR)駅 635m / ラーメン、つけ麺
場所とジャンル: [' 札幌(JR)駅 635m ', ' ラーメン、つけ麺\n ']
ジャンルのタグ: ['ラーメン', 'つけ麺']
----------------------------
お店の名前: 肉処くろべこや
ランチ帯の価格: ~¥999
ディナー帯の価格: ¥4,000~¥4,999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 499m / 焼肉、居酒屋、しゃぶしゃぶ
場所とジャンル: [' さっぽろ(札幌市営)駅 499m ', ' 焼肉、居酒屋、しゃぶしゃぶ\n ']
ジャンルのタグ: ['焼肉', '居酒屋', 'しゃぶしゃぶ']
----------------------------
お店の名前: 三代目 月見軒 札幌駅北口店
ランチ帯の価格: ~¥999
ディナー帯の価格: ~¥999
ジャンルの抽出部分: さっぽろ(札幌市営)駅 468m / ラーメン、餃子
場所とジャンル: [' さっぽろ(札幌市営)駅 468m ', ' ラーメン、餃子\n ']
ジャンルのタグ: ['ラーメン', '餃子']
--------------------------------------------------------
で区切られて20個の店舗情報が出力できているのが分かる。
それではコードの説明を書いていく。
値を抽出する
まず以下の部分だが、これは上記で説明した「ret = soup.find_all(‘div’, {‘class’:’list-rst__rst-data’})」の部分と同じ。findとfind_allを使っていて、対象のhtlmの中からさらにclassを絞ってほしい値を手に入れようとしている。
store_name = ret_item.find('a', {'class':'list-rst__rst-name-target cpy-rst-name js-ranking-num'}).get_text()
score = float(ret_item.find('span', {'class':'c-rating__val c-rating__val--strong list-rst__rating-val'}).get_text())
value = ret_item.find_all('span', {'class':'c-rating-v3__val'})findは一つの値で出るが、find_allはリストで出る。
これはfindメソッドは引数nameで指定されたタグ名を検索し、最初に見つけた要素を値として返すの対して、find_allはすべての要素を返すから。
事実、食べログの今回スクレイピングしたページにおいて「お昼の価格帯」と「夜の価格帯」のところ(以下の赤枠)はクラスが同じでそれぞれ2つある。htlmを見ると以下のような感じ。
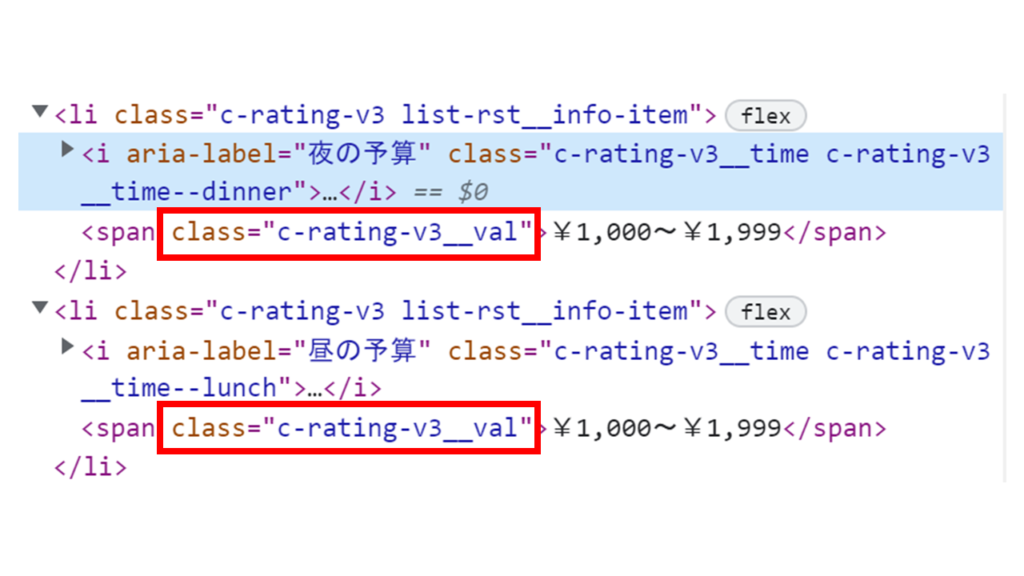
2つの値が入っているところのはspanタグのclassは「c-rating-v3__val」だ。
つまり、リストには2つの値が入っている。
だから「夜の価格帯」の値と「昼の価格帯」の値をそれぞれ得るときは以下のようにリストの1つ目の値と2つ目ので出力する。以下のように。
day_value = value[1].get_text()
night_value = value[0].get_text()このような挙動は途中途中でprintを使ってどんな値がいまどの変数に入っているかを確認しながらコードを書いていくと書いていきやすい。
この上記までで説明したことを頭の中でやろうとすると確実にパンクする。ここ重要。printをしながら確認していくこと。
ちなみに評価の値のところは以下のように書いているが、floatを使って変数として扱えるようにしている。
score = float(ret_item.find('span', {'class':'c-rating__val c-rating__val--strong list-rst__rating-val'}).get_text())値の抽出 + 値の加工
それでは次に進む。次の部分は以下のようになっている。
area_and_ganre = ret_item.find('div', {'class':'list-rst__area-genre cpy-area-genre'}).get_text()
print("ジャンルの抽出部分:", area_and_ganre)
ganre = area_and_ganre.split('/')
print("ジャンルだけ:", ganre)
ganre_tags = ganre[1].split('、')
ganre_tags = [n.replace("\n","").replace(" ","") for n in ganre_tags]
print("ジャンルのタグ:", ganre_tags)以下の部分は大丈夫だろう。上記で説明してきたことと同じことをしている。
area_and_ganre = ret_item.find('div', {'class':'list-rst__area-genre cpy-area-genre'}).get_text()
print("ジャンルの抽出部分:", area_and_ganre)実際に出力された値は以下のようになる。
ジャンルの抽出部分: 札幌(JR)駅 107m / 回転寿司
ここの「回転寿司」のところだけ欲しい。
ここで考えるのは
- ①「/」以下の部分のみを取得するように正規表現で書く
- ②「/」を基に前後2つの部分に分けて、後半の部分を加工する
の2通りの方法があると思う。
今回はイメージしやすい(説明しやすい)、②の方法をとることにする。
まず「/」を基に前後2つの部分に分ける。
これにはsplitを使う。以下の部分である。
ganre = area_and_ganre.split('/')
print("場所とジャンル:", ganre)実際の出力は以下のような感じ。
場所とジャンル: [' 札幌(JR)駅 107m ', ' 回転寿司\n ']ちゃんと2要素に分けられてリストに入っているのが確認できる。このリストの2番目の要素が欲しいわけだが、値がなんか変だ。やけにスペースが多いのが気になるし、「\n」という文言も入ってしまっている。
これを取り除かないといけない。
さらにジャンルによっては以下のように複数ある場合がある。
' スープカレー、カレーライス、ハンバーグ\n 'という事で新たなリストを用意し、複数の値でも扱えるようにし、さらに余計な文字を省くことにする。
複数のジャンルがある場合は「、」で区切られているのでここでもsplitを使う。
この例だとスープカレーとカレーライスとハンバーグのそれぞれが要素としてリストに保存される。
そしてそれぞれの要素に対して余計な文字を省く処理はreplaceを使う。
これをコードにすると以下のようになる。
ganre_tags = [n.replace("\n","").replace(" ","") for n in ganre_tags]
print("ジャンルのタグ:", ganre_tags)このコードは内包表記を使っているがようはfor文を1文で表現しているだけ。1行でかけるのでコードがすっきりするのでおススメだが、for文で書きたい人はfor文でも書けるのでそれでもよい。
で、出力は以下のようになる。
ジャンルのタグ: ['スープカレー', 'カレーライス', 'ハンバーグ']ちゃんとリストになっている🧡
今回のコード全体
ということで、今回のコードをまとめると以下のようになる。
import requests
from bs4 import BeautifulSoup
taberogu_url = "https://tabelog.com/"
todoufuken_item = "hokkaido/A0101"
erea_item = "/A010101"
taberogu_detail_url = taberogu_url + todoufuken_item + erea_item + "/rstLst/1/?Srt=D&SrtT=rt&sort_mode=1"
response = requests.get(taberogu_detail_url)
soup = BeautifulSoup(response.text, 'html.parser')
ret = soup.find_all('div', {'class':'list-rst__rst-data'})
for ret_item in ret:
store_name = ret_item.find('a', {'class':'list-rst__rst-name-target cpy-rst-name js-ranking-num'}).get_text()
score = float(ret_item.find('span', {'class':'c-rating__val c-rating__val--strong list-rst__rating-val'}).get_text())
value = ret_item.find_all('span', {'class':'c-rating-v3__val'})
day_value = value[1].get_text()
night_value = value[0].get_text()
print("お店の名前:", store_name)
print("ランチ帯の価格:", day_value)
print("ディナー帯の価格:", night_value)
area_and_ganre = ret_item.find('div', {'class':'list-rst__area-genre cpy-area-genre'}).get_text()
print("ジャンルの抽出部分:", area_and_ganre)
ganre = area_and_ganre.split('/')
print("場所とジャンル:", ganre)
ganre_tags = ganre[1].split('、')
ganre_tags = [n.replace("\n","").replace(" ","") for n in ganre_tags]
print("ジャンルのタグ:", ganre_tags)
print("----------------------------")結構丁寧に書いたつもりなので、初心者でもスクレイピングをするための参考にしていただければ幸いである。

