
前回は1ページ分の値を取得するプログラムを作成しました。
今回は1つの都道府県分を取得します。
前回は北海道の食べログに注目していましたね。
その中でも札幌に絞り、さらにはその中の札幌駅周辺に絞ったお店を見つけていました。
さて今回は
①札幌駅周辺のお店の情報をできるだけすべて集め、
②その次に札幌のお店の情報をできるだけすべて集め、(←★今回はここまで)
③最後には北海道全土のお店の情報をできるだけすべて集めます。
今回は前回集めた1ページ分の情報を辞書に保存するところから始めましょう。
⓪辞書に情報を保存する

前回のプログラムの不要な部分を削除し、辞書の部分を追加したコードを以下に示します。
不要な部分はコメントアウトし、「😈」マークがついてある行です。追加した行は「✨」マークがついている行になります。
ステップ⓪のコード
import requests
from bs4 import BeautifulSoup
taberogu_url = "https://tabelog.com/"
todoufuken_item = "hokkaido/A0101"
erea_item = "/A010101"
taberogu_detail_url = taberogu_url + todoufuken_item + erea_item + "/rstLst/1/?Srt=D&SrtT=rt&sort_mode=1"
response = requests.get(taberogu_detail_url)
soup = BeautifulSoup(response.text, 'html.parser')
ret = soup.find_all('div', {'class':'list-rst__rst-data'})
count = 0 #✨
info_dict = {} #✨
for ret_item in ret:
store_name = ret_item.find('a', {'class':'list-rst__rst-name-target cpy-rst-name js-ranking-num'}).get_text()
score = float(ret_item.find('span', {'class':'c-rating__val c-rating__val--strong list-rst__rating-val'}).get_text())
value = ret_item.find_all('span', {'class':'c-rating-v3__val'})
day_value = value[1].get_text()
night_value = value[0].get_text()
#print("お店の名前:", store_name) #😈
#print("ランチ帯の価格:", day_value) #😈
#print("ディナー帯の価格:", night_value) #😈
area_and_ganre = ret_item.find('div', {'class':'list-rst__area-genre cpy-area-genre'}).get_text()
#print("ジャンルの抽出部分:", area_and_ganre) #😈
ganre = area_and_ganre.split('/')
#print("場所とジャンル:", ganre) #😈
ganre_tags = ganre[1].split('、')
ganre_tags = [n.replace("\n","").replace(" ","") for n in ganre_tags]
#print("ジャンルのタグ:", ganre_tags) #😈
#print("----------------------------")
info_dict[todoufuken_item.replace("/","_") + erea_item.replace("/","_") + "_" + str(count)] = { \ #✨
'store_name' : store_name, \ #✨
'score' : score, \ #✨
'day_value' : day_value, \ #✨
'night_value' : night_value, \ #✨
'ganre_tags' : ganre_tags \ #✨
} #✨
count = count + 1 #✨
print(info_dict) #✨これを実行すると以下のようになります。見にくいですが、辞書として保存されている事が分かります。(というか順位が前回と変っていますね。。これ直さないとな。。食べログの対象ページの順位が変わると表示されているお店も変わるので収集するときにダブって集める可能性がありますね。。)
{'hokkaido_A0101_A010101_0': {'store_name': '鮨 田なべ', 'score': 3.73, 'day_value': '¥15,000~¥19,999', 'night_value': '-', 'ganre_tags': ['寿司']}, 'hokkaido_A0101_A010101_1': {'store_name': '根室花まる JRタワーステラプレイス店', 'score': 3.7, 'day_value': '¥1,000~¥1,999', 'night_value': '¥1,000~¥1,999', 'ganre_tags': ['回転寿司']}, 'hokkaido_A0101_A010101_2': {'store_name': '味百仙', 'score': 3.7, 'day_value': '¥5,000~¥5,999', 'night_value': '-', 'ganre_tags': ['居酒屋', '日本酒バー', '魚介料理・海鮮料理']}, 'hokkaido_A0101_A010101_3': {'store_name': 'カリーハウス コロンボ', 'score': 3.66, 'day_value': '~¥999', 'night_value': '~¥999', 'ganre_tags': ['カレーライス']}, 'hokkaido_A0101_A010101_4': {'store_name': 'KINOTOYA BAKE JR札幌駅東口店', 'score': 3.66, 'day_value': '~¥999', 'night_value': '~¥999', 'ganre_tags': ['ケーキ', 'スイーツ(その他)']}, 'hokkaido_A0101_A010101_5': {'store_name': 'ぱん吉', 'score': 3.65, 'day_value': '~¥999', 'night_value': '~¥999', 'ganre_tags': ['パン', 'サンドイッチ', 'パン・サンドイッチ(その他)']}, 'hokkaido_A0101_A010101_6': {'store_name': 'フレンチレストラン ミクニ サッポロ', 'score': 3.65, 'day_value': '¥10,000~¥14,999', 'night_value': '¥5,000~¥5,999', 'ganre_tags': ['フレンチ']}, 'hokkaido_A0101_A010101_7': {'store_name': '鉄板焼 やまなみ', 'score': 3.65, 'day_value': '¥15,000~¥19,999', 'night_value': '¥4,000~¥4,999', 'ganre_tags': ['鉄板焼き', 'ステーキ']}, 'hokkaido_A0101_A010101_8': {'store_name': 'ラーメン札幌一粒庵', 'score': 3.64, 'day_value': '~¥999', 'night_value': '~¥999', 'ganre_tags': ['ラーメン', '餃子', '薬膳']}, 'hokkaido_A0101_A010101_9': {'store_name': 'ユーヨーテラスサッポロ ', 'score': 3.63, 'day_value': '-', 'night_value': '¥2,000~¥2,999', 'ganre_tags': ['バイキング', '洋食', '中華料理']}, 'hokkaido_A0101_A010101_10': {'store_name': '函館うに むらかみ 日本生命札幌ビル店', 'score': 3.62, 'day_value': '¥6,000~¥7,999', 'night_value': '¥1,000~¥1,999', 'ganre_tags': ['魚介料理・海鮮料理', '海鮮丼', '懐石・会席料理']}, 'hokkaido_A0101_A010101_11': {'store_name': '175°DENO〜担担麺〜 札幌北口店', 'score': 3.62, 'day_value': '~¥999', 'night_value': '~¥999', 'ganre_tags': ['ラーメン', '担々麺', '居酒屋']}, 'hokkaido_A0101_A010101_12': {'store_name': 'スープカリー ヒリヒリ2号', 'score': 3.61, 'day_value': '¥1,000~¥1,999', 'night_value': '¥1,000~¥1,999', 'ganre_tags': ['スープカレー', 'カレー(その他)', 'ダイニングバー']}, 'hokkaido_A0101_A010101_13': {'store_name': 'スープカリー 奥芝商店 駅前創成寺', 'score': 3.58, 'day_value': '¥1,000~¥1,999', 'night_value': '¥1,000~¥1,999', 'ganre_tags': ['スープカレー', 'カレーライス', 'ハンバーグ']}, 'hokkaido_A0101_A010101_14': {'store_name': 'ショコラティエ\u3000マサール パセオ店', 'score': 3.58, 'day_value': '¥1,000~¥1,999', 'night_value': '¥1,000~¥1,999', 'ganre_tags': ['チョコレート', 'ケーキ']}, 'hokkaido_A0101_A010101_15': {'store_name': 'カリーサボイ', 'score': 3.58, 'day_value': '¥1,000~¥1,999', 'night_value': '¥1,000~¥1,999', 'ganre_tags': ['スープカレー']}, 'hokkaido_A0101_A010101_16': {'store_name': '銀座 篝 札幌店', 'score': 3.57, 'day_value': '¥2,000~¥2,999', 'night_value': '¥1,000~¥1,999', 'ganre_tags': ['ラーメン', 'つけ麺', '居酒屋・ダイニングバー(その他)']}, 'hokkaido_A0101_A010101_17': {'store_name': '麺や ハレル家', 'score': 3.57, 'day_value': '~¥999', 'night_value': '~¥999', 'ganre_tags': ['ラーメン', 'つけ麺']}, 'hokkaido_A0101_A010101_18': {'store_name': 'すし処 北斎', 'score': 3.57, 'day_value': '¥8,000~¥9,999', 'night_value': '¥1,000~¥1,999', 'ganre_tags': ['寿司', '日本酒バー']}, 'hokkaido_A0101_A010101_19': {'store_name': 'ピカンティ 札幌駅前店', 'score': 3.56, 'day_value': '¥1,000~¥1,999', 'night_value': '¥1,000~¥1,999', 'ganre_tags': ['スープカレー']}}ちなみに分かりやすくお店一つ分の情報をjson形式で示すと以下のような感じです。
'hokkaido_A0101_A010101_0': {
'store_name': '鮨 田なべ',
'score': 3.73,
'day_value': '-',
'night_value': '¥15,000~¥19,999', 'ganre_tags': ['寿司']
}さて、辞書ができるようになったので、実際に今度は①のステップ「①札幌周辺のお店の情報をできるだけすべて集め」てみる事にしましょう。
①札幌駅周辺のお店の情報をできるだけすべて集める

まず、札幌駅周辺のお店のランキングページのURLは「https://tabelog.com/hokkaido/A0101/A010101/rstLst/1/?Srt=D&SrtT=rt&sort_mode=1」というものです。
このURLの「A0101」が札幌のコード、「A010101」が札幌駅周辺のコードになっています。そしてrstLstの後ろに「1」がありますが、これがページを表しています。
例えば、これが「2」になると札幌の内(A0101)で札幌駅周辺(A010101)のランキングの2ページ目になります。
まずはこれを60ページまで見て、辞書に入れるようにします。
上記ステップ①のコードを以下のように書き換えます。不要な部分はコメントアウトし、「😈」マークがついてある行です。「✨」がついてある場所が、追加もしくは書き換えた場所です。
ステップ①のコード
import requests
from bs4 import BeautifulSoup
import time #✨
taberogu_url = "https://tabelog.com/"
todoufuken_item = "hokkaido/A0101"
erea_item = "/A010101"
url_elem = todoufuken_item.split('/')
count = 0 #✨
info_dict = {} #✨
for i in range(1, 60): #✨
time.sleep(9) #✨
print(count) #✨
try: #✨
taberogu_detail_url = taberogu_url + todoufuken_item + erea_item + "/rstLst/" + str(i) + "/?Srt=D&SrtT=rt&sort_mode=1" #✨
response = requests.get(taberogu_detail_url)
soup = BeautifulSoup(response.text, 'html.parser')
ret = soup.find_all('div', {'class':'list-rst__rst-data'})
# count = 0 #😈
# info_dict = {} #😈
for ret_item in ret:
store_name = ret_item.find('a', {'class':'list-rst__rst-name-target cpy-rst-name js-ranking-num'}).get_text()
score = float(ret_item.find('span', {'class':'c-rating__val c-rating__val--strong list-rst__rating-val'}).get_text())
value = ret_item.find_all('span', {'class':'c-rating-v3__val'})
day_value = value[1].get_text()
night_value = value[0].get_text()
area_and_ganre = ret_item.find('div', {'class':'list-rst__area-genre cpy-area-genre'}).get_text()
ganre = area_and_ganre.split('/')
ganre_tags = ganre[1].split('、')
ganre_tags = [n.replace("\n","").replace(" ","") for n in ganre_tags]
info_dict[todoufuken_item.replace("/","_") + erea_item.replace("/","_") + "_" + str(count)] = { \
'store_name' : store_name, \
'score' : score, \
'day_value' : day_value, \
'night_value' : night_value, \
'ganre_tags' : ganre_tags \
}
count = count + 1
except Exception as e: #✨
print(str(type(e))) #✨
import traceback #✨
traceback.print_exc() #✨
print(info_dict)
print(len(info_dict))このコードのポイント① countは外に出す
countは全てのお店をカウントするものなのですべてのページをみるためのループである「for i in range(1, 60):」の外で初期化を行います。同様に辞書もfor文の外で初期化を行います。(以下の「👈」がついているところですね)
・・・【略】・・・
count = 0 #👈
info_dict = {} #👈
for i in range(1, 60):
・・・【略】・・・このコードのポイント② 60ページも無い場合を想定してtryとexceptを用いる
食べログのページは60ページまで表示されるとのことですが、60ページない場合も考えられます。そのような場合はURL先のページがないのでエラーが発生してしまいプログラムが停止してしまいます。
それの対策としてtry + exceptを使っています。以下の「👈」ところですね。
・・・【略】・・・
try: #👈
・・・【略】・・・
except Exception as e: #👈
print(str(type(e))) #👈
import traceback #👈
traceback.print_exc() #👈
・・・【略】・・・ このコードのポイント③ time.sleepで待機時間を設ける
以下の行ではtime.sleepを使って9秒間処理を待つことにしています。これは何度もURLにアクセスして攻撃と間違われないようにするためです。
time.sleep(9)9秒ごとに1回for文内の処理が行われます。
ちなみに最大で9秒×60ページ=540秒かかることになります。
9分間プログラムが何も応答ないと怖くなるので途中でcountはprintしています。
print(count)このコードのポイント④ ちゃんと辞書に保存できているかはlen()も使って確認する
最後にちゃんと情報が集められているかを確認します。
ただ、すごい量なのでただ単に辞書をprintするよりはlenも使って何件辞書に入っているかを確認しています。
②札幌のお店の情報をできるだけすべて集める
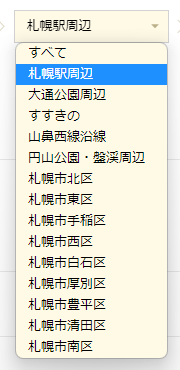
ここで札幌のお店の情報を集める前に軽く見積もりをしておきましょう。
札幌エリアだけでみても、上記までに集めた「札幌駅周辺」を含めて14ヶ所あります。(以下のように)
上記で書いたように1ページ9秒で集めると1エリア辺り最大540秒かかります(60×9)ので、540×14=7560秒(126分)はかかる可能性があります。
さらに北海道は札幌エリア以外にも10エリアあるわけで、126分×10=1260分で21時間かかる危険性があります。21時間かからないにしてもかなりの時間が必要だと見込まれます。
長時間プログラムのためにパソコンを起動しておきたくはないので北海道に関してはラズベリーパイで取得したいと思っています。
とりあえず、札幌エリアに関しては最大126分なので集めちゃいます。
そしてせっかくなんでcsv出力もしてみます。データとして残せるように。
csv出力するので辞書の形式も少し変えます。
ではコードを見ていきましょう。
ステップ②のコード
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
taberogu_url = "https://tabelog.com/"
todoufuken_item = "hokkaido/A0101"
erea_item = "/A010101"
url_elem = todoufuken_item.split('/')
count = 0
info_dict = {}
for erea_num in range(1, 30): #✨
if erea_num < 10: #✨
erea_item = url_elem[1] + "0" + str(erea_num) #✨
elif erea_num >= 10: #✨
erea_item = url_elem[1] + str(erea_num) #✨
for i in range(1, 60):
time.sleep(9)
try:
taberogu_detail_url = taberogu_url + todoufuken_item + "/" + erea_item + "/rstLst/" + str(i) + "/?Srt=D&SrtT=rt&sort_mode=1" #✨
response = requests.get(taberogu_detail_url)
soup = BeautifulSoup(response.text, 'html.parser')
ret = soup.find_all('div', {'class':'list-rst__rst-data'})
for ret_item in ret:
store_name = ret_item.find('a', {'class':'list-rst__rst-name-target cpy-rst-name js-ranking-num'}).get_text()
score = float(ret_item.find('span', {'class':'c-rating__val c-rating__val--strong list-rst__rating-val'}).get_text())
value = ret_item.find_all('span', {'class':'c-rating-v3__val'})
day_value = value[1].get_text()
night_value = value[0].get_text()
area_and_ganre = ret_item.find('div', {'class':'list-rst__area-genre cpy-area-genre'}).get_text()
ganre = area_and_ganre.split('/')
ganre_tags = ganre[1].split('、')
ganre_tags = [n.replace("\n","").replace(" ","") for n in ganre_tags]
info_dict[todoufuken_item.replace("/","_") + erea_item.replace("/","_") + "_" + str(count)] = { \
'store_name' : store_name, \
'score' : score, \
'day_value' : day_value, \
'night_value' : night_value, \
'ganre_tags' : ganre_tags \
}
count = count + 1
except Exception as e:
print(str(type(e)))
import traceback
traceback.print_exc()
print(len(info_dict))
output_df = pd.DataFrame(info_dict)
output_df.to_csv('./result/erea_data_' + url_elem[1] + "_" + url_elem[0] + '.csv', encoding='utf_8_sig')エリアのところを変数にしてfor文でループを回すようにしました。
30か所以上はないだろうという見込みで1~30のループを回します。
ここはこれだけです。
というかこれだと30×60×9秒かかりますね。4.5時間かかります。😨
ま、まあ休日にプログラムを動かしておくことにします。
③北海道全土のお店の情報をできるだけすべて集める(次回予告)
ここから北海道全土を集めるという事なのですが、まあパソコンだときついです。なのでラズベリーパイで集めることにします...というのは次回行います。
今回はここまでにします。長くなっちゃったんでね。

