
今回やること
前回までで評価までできました。
あまり精度が良くなかったですね。
どういうデータの予測が当たっていて、どういうデータの予測が外れているか知るために、今回は残差分析をしてみます。
※結果から言うとあまり精度は良くなりませんでした。
残差分析というのは、予測値と実際の値の差(残差)を分析することです。
前回、実際の値と予測した値をプロットしたグラフまで載せました。
それが以下のグラフですが、3.7以下から幅が広くなっていますね。(以下はランチの結果です)
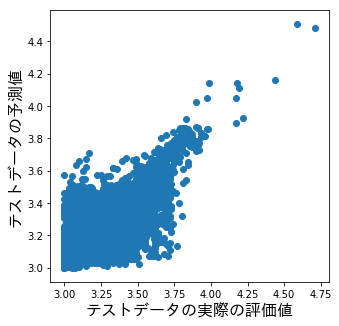
つまり、実際の評価値より過小評価されているものもあるし、過大評価されているものもある訳です。
そこで、実際の値 – 予測した値が大きいもの、つまり、過小評価で予測されたものを上位100件まで求めて分析していきたいと思います。
また、その逆、実際の値 – 予測した値が小さいもの、過大評価された上位100件も分析していきます。
※前回はランチとディナーで分けて見てみましたが、今回は試しにランチだけで見てみます。
その分析結果から再度モデルを構築して精度を測ってみます。
分析
suumoの物件の分析と同じコードを用いるので、今回はコードは割愛します。
こちらのコードとほぼ同じです。
参考にしてみてください。
また、一つ一つの説明変数に対する結果を載せると長くなってしまうので、気になったところだけピックアップしていきます。
気になったところ
気になったところ①:個室
すんません、個室の有無に関しては、過大評価されている上位で表示させたら以下のようになりました。
無 93 有 1 有(4人可) 1 無1Fビヤホールは全てテーブル席です。個室はございませんが、おひとり様~団体様まで幅広くご利用いただけます。 1 無テイクアウト専門店 1 無半個室あり 1 有(4人可)小上がり4名席、半個室となります。※お誕生日や、ご接待で4名様以上のお客様は、完全貸切営業が可能です。カウンター席もご利用頂けます。 1 有(2人可、4人可、6人可)カウンター席半個室あり 1
無と有でいいですね、これ。
気になったところ②:価格帯
ランチの結果に関してですが、過大評価されたものの上位100位に含まれていた価格帯別の個数が以下。
~¥999 65 ¥1,000~¥1,999 25 ¥3,000~¥3,999 3 ¥10,000~¥14,999 2 ¥2,000~¥2,999 2 ¥20,000~¥29,999 1 ¥8,000~¥9,999 1 ¥15,000~¥19,999 1
過小評価されたものの上位100位に含まれていた価格帯別の個数が以下。
~¥999 46 ¥1,000~¥1,999 33 ¥2,000~¥2,999 6 ¥8,000~¥9,999 5 ¥10,000~¥14,999 3 ¥6,000~¥7,999 2 ¥4,000~¥4,999 2 ¥3,000~¥3,999 2 ¥5,000~¥5,999 1
ほとんどが~¥999と¥1,000~¥1,999の価格帯に集中しています。
確かに、そもそもこの2つの価格帯のお店が多い事が良そうとも言えますが、一方で安いレストランの中では何かまだ評価値を左右するパラメータが別にあるかもしれないことも同時に予想されます。
気になったところ③:ジャンル
お次に、ジャンルで出力させてみました。
✅ランチの過大評価のもの上位100件に含まれていた上位10ジャンル
ラーメン 28 カフェ 19 パン 10 ケーキ 10 カレー 8 つけ麺 7 サンドイッチ 5 インドカレー 5 洋食 4 洋菓子 4
✅ランチの過小評価のもの上位100件に含まれていた上位10ジャンル
ラーメン 39 つけ麺 16 居酒屋 13 カレー 11 フレンチ 10 カフェ 10 日本料理 6 パン 6 海鮮 6 ワインバー 4
「ラーメン」、「つけ麺」、「カフェ」、「パン」、「カレー」が過大評価と過小評価のどちらにもありますね。
「気になったところ②:価格帯」と「気になったところ③:ジャンル」がリンクした気がしました。
確かに「ラーメン」とかって金額はどこも同じだけど、評価が変わってきますね。
「イタリアン」や「フレンチ」とかと違って「ラーメン」とかはお店ごとに金額はあまり変わらない。
だから金額やお店の地域では差別化できず、予測しにくいってことになりますね。
再学習する
ということで、以下を変更して再学習して見ます。
- 「ラーメン」、「つけ麺」、「カフェ」、「パン」、「カレー」のジャンルのお店を除く
- 個室を「無」と「有」(あとからの場合はNaN)にする
ランダムフォレストを再度実施した結果は以下。
0.04890363790927997 👈学習データへの回帰に対するRMSE 0.11405710862773752 👈テストデータへの回帰に対するRMSE
改善前の結果は以下。
0.05543106695342894 👈学習データへの回帰に対するRMSE 0.12260458899754725 👈テストデータへの回帰に対するRMSE
ちょっとだけ良くなってますね。
ちょっとだけ。
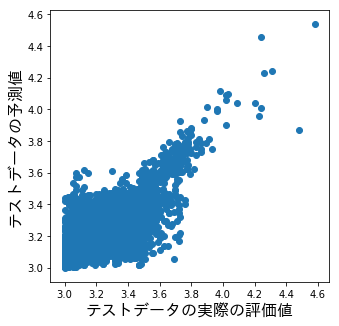
ちなみに、テストデータの実際の評価値とテストデータの予測値をプロットした結果は以下です。
重要度
参考までに重要度も載せておきます。
受賞アワードの数 : 0.16074389631320649 ランチの価格帯 : 0.06377717494622961 デート(利用シーン) : 0.014064824651429492 東京のエリア_中央区 : 0.01017253530332854 東京のエリア_新宿区 : 0.009700643354363842 オシャレな空間 : 0.008071138139959504 東京のエリア_千代田区 : 0.008064892718563263 家族・子供と : 0.007939949144569297 東京のエリア_港区 : 0.0076884388401269 東京のエリア_台東区 : 0.007353125403532159 東京のエリア_渋谷区 : 0.0072437625353390335 東京のエリア_世田谷区 : 0.006415617160240905 コンビニ・スーパー : 0.005779800854311395 野菜料理にこだわる : 0.0054292582789861495 カクテルあり(飲み物) : 0.005045072748514294 日本酒あり(飲み物) : 0.0044461627683416854 東京のエリア_豊島区 : 0.004411980554455128 東京のエリア_目黒区 : 0.004267212070394552 焼酎あり(飲み物) : 0.00398335474342556 居酒屋(ジャンル) : 0.0038744166458869857
まとめ
今回は東京の食べログのランチのデータに対して残差分析を行い、前回のランダムフォレストより良くなるようにしました。
たしかにほんのちょっとだけ精度は上がりました。
ただ、決して凄い良いわけではないです。
また改善策を考え、チャレンジをしてみます。
今回はここまで。ではまた👋👋👋

