
はじめに
前回は東京の家賃をボックスプロットを用いて可視化しました。
今回は家賃推定をすることで、その家賃を決定づける値は何なのかを調べていきます。
前回と同様、家賃は「家賃 + 管理費/共益費」です。
たまに管理費/共益費がめちゃくちゃ高くて、家賃が安めという物件もありますからね!
逃しませんよ~~。
回帰分析
今回は重回帰分析とランダムフォレストで調べてみました。
重回帰分析
まずは重回帰分析です。
コードは以下のような感じ。
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.metrics import mean_absolute_error as MAE
import numpy as np
clf = linear_model.LinearRegression()
select_columns = ['築年数', '部屋の向き', '部屋の広さ', '階数', '駅からの距離', '近い駅', 'ユニットバスかどうか']
train_data = pd.get_dummies(room_shape_date[select_columns], drop_first=True)
y_data = room_shape_date['家賃']
X_train, X_test, y_train, y_test = train_test_split(train_data, y_data, test_size=0.2, shuffle=True)
clf.fit(X_train, y_train)
y_pred_train = clf.predict(X_train)
mae_train = MAE(y_train, y_pred_train)
print(mae_train)
y_pred_test = clf.predict(X_test)
mae_test = MAE(y_test, y_pred_test)
print(mae_test)実行結果は以下です。
1.0947867912200748 1.1605027480963577
上の値はMAEを用いて訓練データを評価した値です。
下の値はMAEを用いてテストデータを評価した値です。
単位は万円なので、誤差で1万円ほど出てしまっています。
今回説明変数として使ったのは
['築年数', '部屋の向き', '部屋の広さ', '階数', '駅からの距離', '近い駅', 'ユニットバスかどうか']
です。
これは過学習が起きていたので、使う説明変数を変えていって何とか上記の誤差になるまで改善していった結果になります。
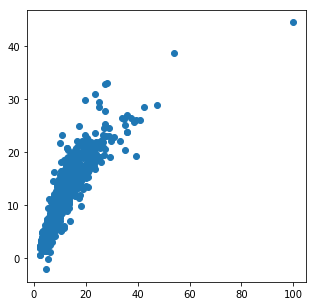
以下の散布図は実際のテストデータと重回帰モデルを用いてテストデータを予測したデータを表しています。
縦軸が重回帰モデルを用いてテストデータを予測したデータで横軸が実際のテストデータの値になります。
単位は万円です。
ランダムフォレスト
次はランダムフォレストで回帰させてみます。
コードは以下のような感じ。(ほぼ、重回帰分析の時と同じですね。)
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as MAE
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
select_columns = ['築年数', '部屋の向き', '部屋の広さ', '階数', '駅からの距離', '近い駅', 'ユニットバスかどうか', '室内洗濯機置場' ]
train_data = pd.get_dummies(room_shape_date[select_columns], drop_first=True)
y_data = room_shape_date['家賃']
X_train, X_test, y_train, y_test = train_test_split(train_data, y_data, test_size=0.2, random_state=1234, shuffle=True)
frf = RandomForestRegressor()
frf.fit(X_train, y_train)
y_pred_train = frf.predict(X_train)
mae_train = MAE(y_train, y_pred_train)
print(mae_train)
y_pred_test = frf.predict(X_test)
mae_test = MAE(y_test, y_pred_test)
print(mae_test)
print(frf.score(X_test,y_test))出力結果は以下になります。
0.24971512544264188 0.5609980078829842 0.943176290267526
訓練データとその予測値間のMAEの値の値が2倍近く離れているため、過学習が見込まれています。
これも重回帰分析の時と同様に、実際のテストデータとランダムフォレストを用いてテストデータを予測したデータを表した散布図を以下に載せておきます。
縦軸が重回帰モデルを用いてテストデータを予測したデータで横軸が実際のテストデータの値になります。
単位は万円です。
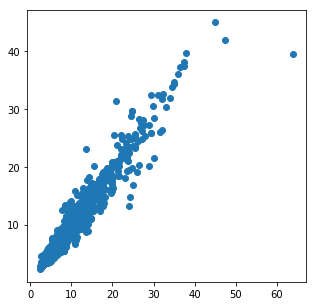
確かに気持ち予測値の方が高めに予測されてしまっています。
過学習をしている時の対策として、ハイパーパラメータを調整していく必要がありそうです。
そこでグリッドサーチをしてみます。
グリッドサーチ
グリッドサーチはハイパーパラメータを最適化するための手法です。
以下がコードになります。
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as MAE
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
select_columns = ['築年数', '部屋の広さ', '場所', '階数', '駅からの距離', '近い駅', 'ユニットバスかどうか', '室内洗濯機置場' ]
train_data = pd.get_dummies(room_shape_date[select_columns], drop_first=True)
y_data = room_shape_date['家賃']
X_train, X_test, y_train, y_test = train_test_split(train_data, y_data, test_size=0.2, random_state=1, shuffle=True)
parameters = {
'n_estimators': [50, 100, 300, 500, 1000], # 決定木の数
'max_features': ['sqrt', 'log2','auto', None], # 利用する特徴量
'max_depth': [10, 20, 30, 40, 50, None], # 決定木の深さ
'random_state': [1]
}
frf = RandomForestRegressor()
# ハイパーパラメータチューニング(グリッドサーチのコンストラクタにモデルと辞書パラメータを指定)
gridsearch = GridSearchCV(estimator = frf, # モデル
param_grid = parameters, # ハイパーパラメータ
scoring = "r2" # スコアリング
)
gridsearch.fit(X_train, y_train)
# グリッドサーチの結果から得られた最適なパラメータ候補を確認
print('Best params: {}'.format(gridsearch.best_params_))
print('Best Score: {}'.format(gridsearch.best_score_))出力は以下のようになりました。
Best params: {'max_depth': 40, 'max_features': 'auto', 'n_estimators': 50, 'random_state': 1}
Best Score: 0.9185972624804215
パラメータのチューニングができたところで再度ランダムフォレストで学習させます。
以下のコードのハイライトのところがグリッドサーチで求めた値で設定しています。これで再度実行します。
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as MAE
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
select_columns = ['築年数', '部屋の広さ', '場所', '階数', '駅からの距離', '近い駅', 'ユニットバスかどうか', '室内洗濯機置場' ]
train_data = pd.get_dummies(room_shape_date[select_columns], drop_first=True)
y_data = room_shape_date['家賃']
X_train, X_test, y_train, y_test = train_test_split(train_data, y_data, test_size=0.2, random_state=1234, shuffle=True)
frf = RandomForestRegressor(max_depth=40, n_estimators=50, random_state=1)
frf.fit(X_train, y_train)
y_pred_train = frf.predict(X_train)
mae_train = MAE(y_train, y_pred_train)
print(mae_train)
y_pred_test = frf.predict(X_test)
mae_test = MAE(y_test, y_pred_test)
print(mae_test)
print(frf.score(X_test,y_test))実行結果は以下です。
0.21887078185228773 0.5603685522196561 0.9434882138552257
いや、ちょっと訓練データの精度が上がっただけやないかいっ!
重要度を求める
これが、精度の限界だと諦め、最後に重要度を求めようと思います。。
各特徴量にどのくらいの重要度があるかを調べようということです。
コードとしては以下のようにしています。
labels = X_train.columns
importances = frf.feature_importances_
dictionary = {k: v for k, v in zip(labels, importances)}
top_items = sorted(dictionary.items(), key=lambda x: x[1], reverse=True)[:20]
bottom_items = sorted(dictionary.items(), key=lambda x: x[1])[:20]
for key, value in top_items:
print(key,": ", value)
print("-----------")
for key, value in bottom_items:
print(key,": ", value)今回は特徴量が414個あるので、影響度の高い重要度20位と影響度の低い重要度20位を載せておきます。
まずは、影響度の大きい重要度20位。
部屋の広さ : 0.45490651521011893 tokyo_area_港区 : 0.13339525510693057 築年数 : 0.12525839402567415 tokyo_area_中央区 : 0.1110001610104453 tokyo_area_渋谷区 : 0.026485705125961326 階数 : 0.02467285817433082 駅からの近さ : 0.023639145789486175 tokyo_area_練馬区 : 0.010385812595103436 tokyo_area_武蔵野市 : 0.0060718737228410875 tokyo_area_世田谷区 : 0.005986764696788487 tokyo_area_青梅市 : 0.004923754908265496 tokyo_area_福生市 : 0.0034042847582249386 tokyo_area_墨田区 : 0.0029527279075704086 tokyo_area_北区 : 0.0028038947825847526 tokyo_area_足立区 : 0.002596800828617687 tokyo_area_新宿区 : 0.0025026248688184882 tokyo_area_台東区 : 0.0021174087450695584 tokyo_area_江戸川区 : 0.0020652856139232057 tokyo_area_日野市 : 0.0019974254601520997 nearest_station_汐留駅 : 0.0017185614998779086
部屋の広さがダントツで家賃に影響していることが分かります。
また、港区、中央区、渋谷区に物件があると階数や駅からの近さよりも家賃に影響するのでこれらの場所は注意が必要ですね。
次に、影響度の低い重要度20位
nearest_station_十条駅 : 0.0 nearest_station_古里駅 : 0.0 nearest_station_方南町駅 : 0.0 nearest_station_東秋留駅 : 0.0 nearest_station_武蔵五日市駅 : 0.0 nearest_station_立川北駅 : 0.0 nearest_station_片倉駅 : 1.4998811491771576e-08 nearest_station_高輪ゲートウェイ駅 : 1.558170413758154e-08 nearest_station_中神駅 : 1.635395498328102e-08 nearest_station_白糸台駅 : 8.615546795167122e-08 nearest_station_多磨霊園駅 : 9.181046749403591e-08 nearest_station_小台駅 : 9.250322122370748e-08 nearest_station_大山駅 : 1.198364314342884e-07 nearest_station_小田急多摩センター駅 : 1.4673368257818912e-07 nearest_station_京王永山駅 : 1.887484798372046e-07 nearest_station_昭島駅 : 2.0436325412279255e-07 nearest_station_堀切駅 : 2.4168972897219076e-07 nearest_station_梶原駅 : 2.46298670273749e-07 nearest_station_多磨駅 : 2.9242581922416426e-07 nearest_station_牛田駅 : 3.744036149722832e-07
駅ばっかりですね。
上記の駅の最寄りの物件は特にどこに住んでもそこまで家賃には影響してませんね。
上記の駅の最寄りの物件で悩んでいたら、より自分のわがままに従っても特に家賃で損することはないですね。
おわりに
今回は、家賃を重回帰分析とランダムフォレストで分析し、最後には重要度を求めてみました。
実際に数字で出されると物件を選ぶ際の説得力のある根拠になりますね。
次回は、すべてのデータの家賃に対して予測値を求め、その中でも本来の家賃より安い物件に対してフォーカスして調査を進めていきたいと思います。
今回はここまで。ではまた。👋👋👋

