
はじめに
今まで東京ディズニーランドの待ち時間を予測してきました。
しかし、本来の目的は天気予報情報などの事前に分かっている情報からディズニーランドの待ち時間を予測できるかというところにあります。
今回はそれをします。
学習と予測結果
学習にはランダムフォレストを用いています。
上記でも軽く触れた通り、アトラクションやレストランの待ち時間という当日でしかわからない情報は省いて学習しています。
データはその日の14時の時の待ち時間と天気のデータを用いています。
ディズニーランドとディズニーシーの両方で求めました。
ディズニーランド
まずは、ディズニーランドからです。
今回はアトラクション「美女と野獣」の待ち時間を予測してみました。
学習とテストの評価は以下のようになりました。
学習データに対する回帰への評価(RMSEの値): 9.153910815233917
学習データに対する決定係数: 0.9288369904630196
テストデータに対する回帰への評価(RMSEの値): 23.678457430000964
テストデータに対する決定係数: 0.4134709530374572
テストデータの決定係数を見てみると分かるように、あまり良くない結果になりました。
ちなみに元のデータ数は434です。(nanの多いアトラクションは省いて、その後にその時点であるアトラクションのデータ内のnanを省いた数)
結構少ないです。(と言っても、1日1データなので1年と2ヶ月分くらいのデータです)
「美女と野獣」の待ち時間の実際の値と予測した値との関係散布図を載せておきます。
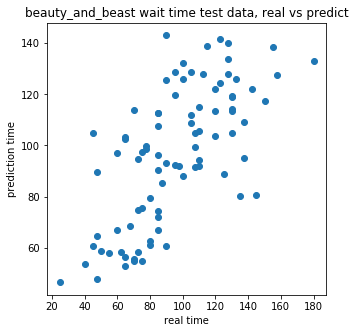
精度があまり良くないので、まだ幅がありますね。
次に、重要度の値になります。
dew_point : 0.49334019538309754
feels_like : 0.10891485499287355
temp : 0.07249760211960328
wind_speed : 0.05307430639508683
humidity : 0.04158695044570079
pressure : 0.04119056485890303
wind_deg : 0.0384349485607979
visibility : 0.033682242028475425
clouds : 0.012922342866369113
シンデレラの誕生日 : 0.012869425430116977
dew_point(結露し始める点)がとても予測に対して影響力がありますね。
ディズニーシー
続いて、ディズニーシーの結果です。
学習とテストの評価は以下のようになりました。
ディズニーシーでは「ソアリン」というアトラクションの待ち時間を予測してみました。
学習データに対する回帰への評価(RMSEの値): 12.244428626738284
学習データに対する決定係数: 0.9167383097219197
テストデータに対する回帰への評価(RMSEの値): 31.64836443410886
テストデータに対する決定係数: 0.38739470013206534
こちらもディズニーランドと同様にあまり良くない結果ですね。
元データの数は478です。
やはりまだ少ないか。。。
「ソアリン」の待ち時間の実際の値と予測した値との関係散布図は以下です。
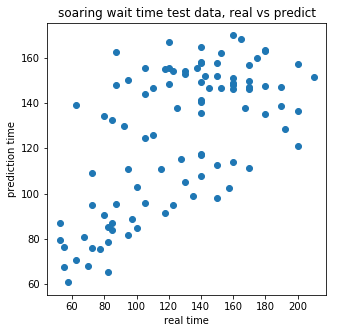
重要度は以下のようになりました。
dew_point : 0.47632231462659924 pressure : 0.07973858444808526 temp : 0.07956701437563889 feels_like : 0.07926030243911876 wind_deg : 0.0656208747382978 humidity : 0.054660756579752404 wind_speed : 0.05334130372767831 clouds : 0.02286398771969722 visibility : 0.021719664024395558 event_num : 0.007998188975947281
こちらもdew_point(結露し始める点)がとても予測に対して影響力があることが分かります。
最後に
来年の1月にデータを集め直して、データ数を増やしてリベンジやね。
