
皆さんはワイン飲んでますか?
私は飲んでます。
ちょっとだけ。
ワインって安いものから高いものまでありますね。
ここにもコスパが潜んでそうです。
ちなみに「安いワイン」という本があります。
この本では安いワインでもおいしく楽しむ術が書かれています。
興味があれば読んでみてください。
kindle unlimitedでも読めます
可視化
今回の分析ではkaggleにあったワインのデータを使用しています。
データはこちらから取得できます。

今回の分析は今までの食べログの分析やsuumoの分析と同様に、まずは評価値と他の値との間のボックスプロットを表示し、その後にランダムフォレストを使った分析をしていきます。
国と評価値との関係
国ごとの評価値のボックスプロットは以下のようになります。
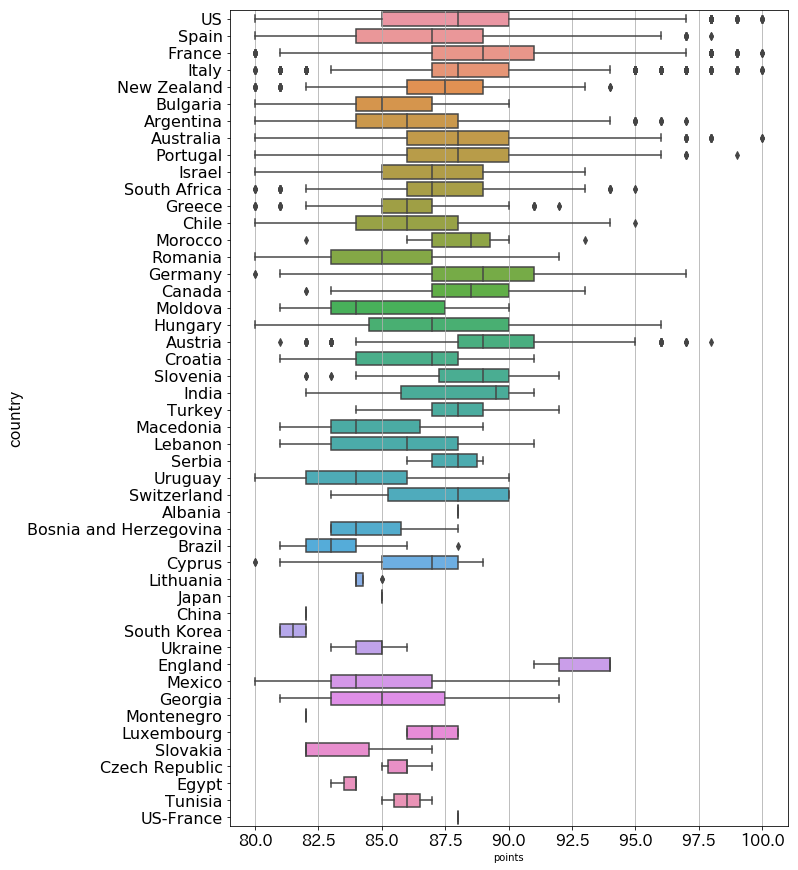
イギリス(England)の評価値がとても高いですね。
韓国(South Korea)のワインの評価値は低めです。
国と金額の関係
国ごとの金額のボックスプロットは以下のようになります。
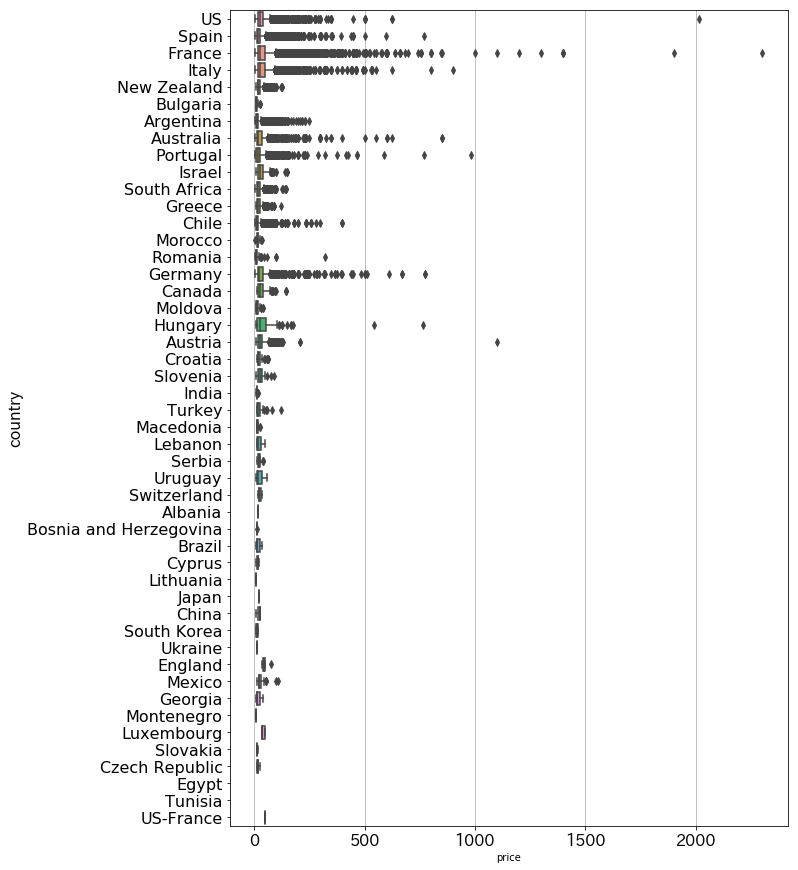
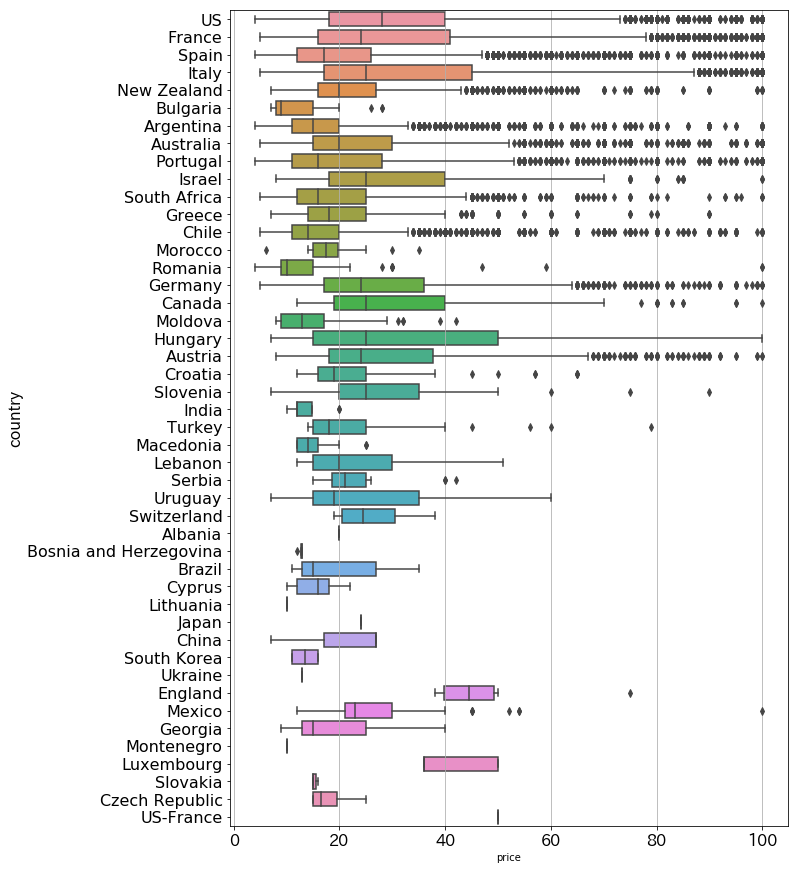
高すぎるワインがあってボックスプロットが潰れてしまっているので、$100以下のワインに限定して表示してみます。
次に金額と評価値をプロットしてみます。
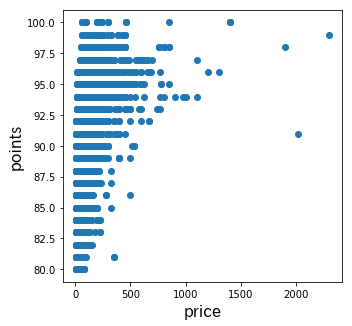
高いワインも評価(points)は高めにはなっていますが、安くても評価が高いワインはありますね。
そここそがコスパの良いワインなのでしょうね。
ランダムフォレスト

次にランダムフォレストをやってみます。
評価値
まずは評価値について見てみます。
ランダムフォレストで回帰をしてみて、評価値を推定します。
その推定値よりも、実際の評価値が高ければそれはコスパが良く、逆に低ければコスパが悪いということになります。
csvファイルをDataframeとして読込み
import pandas as pd
wine_df = pd.read_csv("./data/wine/winemag-data_first150k.csv")priceとpointsは数値として扱うためにfloat型へ。
wine_df['points'] = wine_df['points'].astype(float)
wine_df['price'] = wine_df['price'].astype(float)price以外は質的変数なのでダミー変数化が必要です。
しかし、以下のように値の種類を出すと、9,7821種類の値があり、実際に実行するとメモリーエラーが発生するので、ここではdescriptionカラムの値は使わないことにしました。
print(wine_df['country'].nunique())
print(wine_df['description'].nunique())
print(wine_df['designation'].nunique())
print(wine_df['province'].nunique())
print(wine_df['region_1'].nunique())
print(wine_df['region_2'].nunique())
print(wine_df['variety'].nunique())
print(wine_df['winery'].nunique())実行結果
48 97821 30621 455 1236 18 632 14810
ランダムフォレストのコードは以下のような感じ。
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
import numpy as np
from sklearn.ensemble import RandomForestRegressor
select_columns = ['price', 'country', 'designation', 'province', 'region_1', 'region_2', 'variety', 'winery']
wine_df = wine_df.dropna()
train_data = pd.get_dummies(wine_df[select_columns], drop_first=True)
y_data = wine_df['points']
X_train, X_test, y_train, y_test = train_test_split(train_data, y_data, test_size=0.3, random_state=1, shuffle=True)
frf = RandomForestRegressor()
frf.fit(X_train, y_train)
y_pred_train = frf.predict(X_train)
mae_train = np.sqrt(MSE(y_train, y_pred_train))
print(mae_train)
y_pred_test = frf.predict(X_test)
mae_test = np.sqrt(MSE(y_test, y_pred_test))
print(mae_test)
print(frf.score(X_test,y_test))実行結果は以下。
1.155741659476716 2.1840715382638765 0.5942788418423633
あんま精度良くないですね。😓😓
あと、グリッドサーチでハイパーパラメータを調整しようとしましたが、恐ろしく時間がかかるので断念。
テストデータの実際の値と予測値をプロットした散布図は以下です。赤い線の上の緑の領域にあるものが予測値よりも実際の評価値が高い事になります。
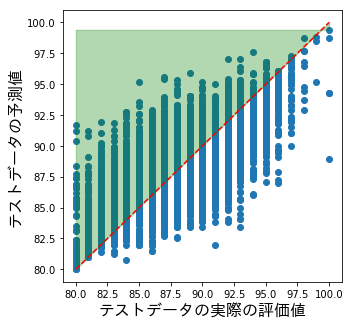
確かに実際の値が上昇していくと気持ち予測値も上がっていくようなグラフにはなっています。
ちなみに重要度のベスト10を出力させてみました。以下になっています。
price : 0.324353287160611 province_Washington : 0.015084596932437305 region_1_Paso Robles : 0.011569470534079142 variety_Chardonnay : 0.010379306213326146 region_2_Columbia Valley : 0.005934072156496285 variety_Red Blend : 0.00530792909107239 variety_Pinot Noir : 0.004641911134012242 winery_Williams Selyem : 0.004582739687083024 designation_Reserve : 0.0040110111645561865 variety_Merlot : 0.0037550334505327
一番は金額が評価に影響するとのことでした。
ただし、32%ぐらいなのでそこまで大きな影響ではありません。
provinceはワインの産地を示しますので、province_Washingtonというのはワシントンで作られたワインは評価が少し高めになる影響があるということです。
といっても、1.5%ほどの影響ですね。
それ以降も低い影響度ですね。
region_1もワインの生産地を表すようです。(provinceとの違いは何なんだ…。より細かな領域ということですかね。)
3位のPaso Roblesはカリフォルニアにある都市です。
varietyはワインを作るためのブドウの品種です。
4位のChardonnay(シャルドネ)は白ワイン用のブドウの品種になります。
region_2はさらに具体的な生産地です。5位のColumbia Valleyはワシントン州中部と南部、オレゴン州らへんです。
金額
次に金額に対してランダムフォレストをやっていきます。
コードは評価値の時と同じ(説明変数に評価値を入れて、目的変数を値段に変更しただけ)なので割愛します。
またモデルの評価に関しては評価値の場合はMSEを使用して評価しましたが、金額は外れ値が多いため、MAEを使用して評価しました。
また、金額は外れ値も結構あると精度が悪くなってしまう懸念から、$500以下のワインに絞って行いました。(最初は外れ値も含めて試しましたが、精度が悪いので$500以下に絞りました)
結果としては以下のようになりました。
学習データのMAE→ 2.349439436678842 テストデータのMAE→ 5.938886691045203 テストデータの評価(score)→ 0.758074233717055
評価値の時よりはスコアが良くなってますね。
MAEの結果からだとテストデータで過学習を起こしているようにも見えますが…。
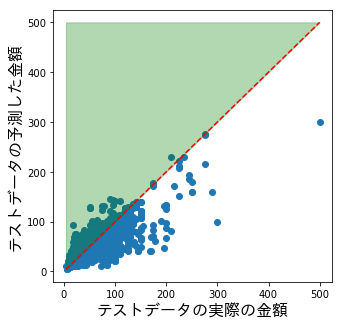
テストデータの実際の値と予測値をプロットした散布図は以下です。
評価値と同様、緑で塗られたところが実際の金額よりも予測した金額の方が高くなっており、予測した金額より安い領域になります。
重要度のベスト10を金額でも出力。以下です。
points : 0.25404607016408953 region_2_Napa : 0.12001016636440517 variety_Pinot Noir : 0.04135199088538685 winery_BOND : 0.038300751257810135 variety_Cabernet Sauvignon : 0.03329935902769167 variety_Bordeaux-style Red Blend : 0.01725841256394363 region_1_California : 0.008192876514207534 winery_Verité : 0.007132330517959295 winery_Diamond Creek : 0.00606911839710902 winery_Colgin : 0.006063577669270999
金額には一番評価値が影響してますね。
2位のナパで生産されたワインも高めになるようです。
ナパはカリフォルニア州にあり、世界的高級ワインの聖地として知られているらしいです。
流石、影響してきますね。
3位のPinot Noir(ピノ・ノワール)は主に赤ワイン用に栽培されるヨーロッパのブドウ品種です。
4位のBONDはナパにあるワイナリーです。またナパが出てきましたね。さすがですね。
5位のCabernet Sauvignon(カベルネ・ソーヴィニヨン)は赤ワイン用のブドウ品種です。
世界で最も広く栽培されていることもあり、5位に入ってきたのでしょうかね。
まとめ(今回得たこと)
今回はkaggleのデータを使用してワインを分析して見ました。
実際に可視化をすることで大まかな値の分布がわかりました。
ランダムフォレストを用いて評価値を求めましたが、精度はそこまで高いものは求められませんでした。
それだけワインは奥が深いということなのですかね。
金額に関しては評価値をよりは良い精度を出せましたが、決して高い精度ではありませんでした。
非常に複雑な世界ですね。
評価値は説明変数が適切では無かった可能性も十分にあり得ます。
次回以降は今回のランダムフォレストの結果から実際にデータを見てみてどういうワインがコスパが良いのかを実際に見ていこうと思っています。
また、パラメータに関しても別の視点からアプローチができればと思います。
今回はここまでにします。ではまた。👋👋👋
その他、ワインの広告

