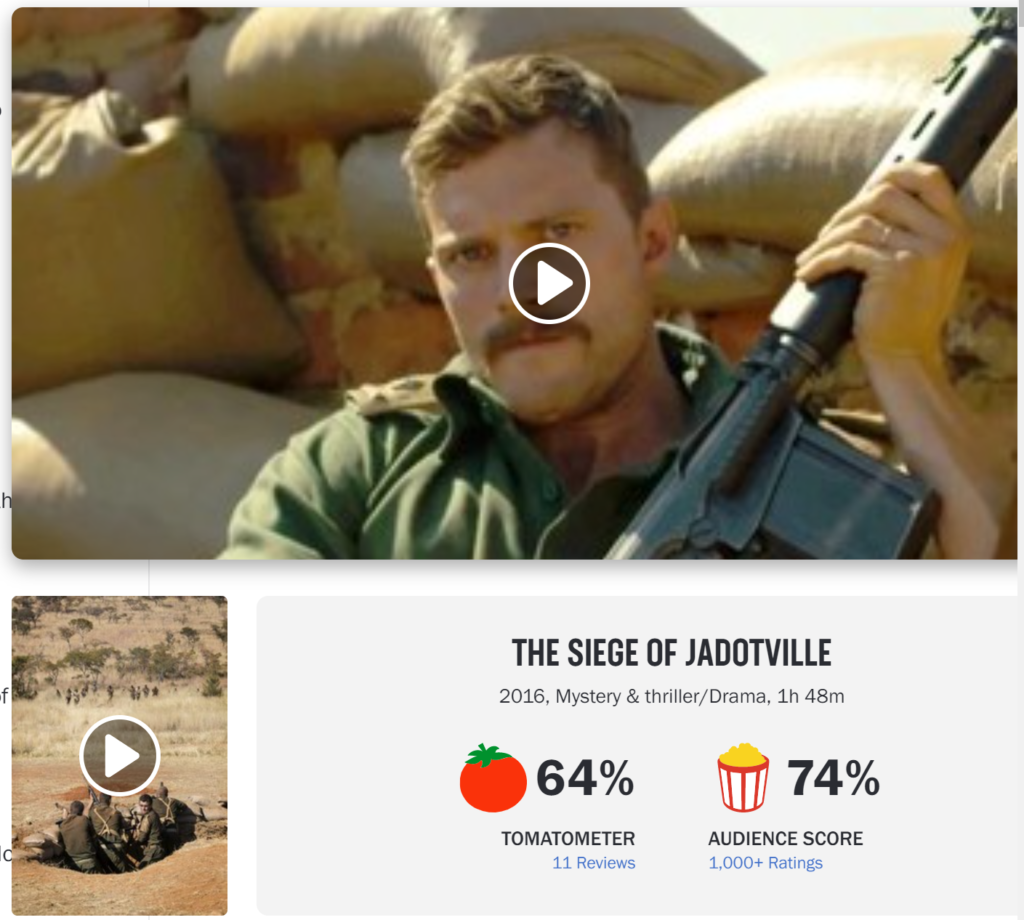
一方、同じ2016年の作品でも製作された年がURLに入っていない作品もあります。例えば、『BRAHMAN NAMAN』や『THE SIEGE OF JADOTVILLE』がそうです。
『BRAHMAN NAMAN』であれば「https://www.rottentomatoes.com/m/brahman_naman」、『THE SIEGE OF JADOTVILLE』であれば「https://www.rottentomatoes.com/m/the_siege_of_jadotville」という感じです。
例えば、wikipediaでは「True Memoirs of an International Assassin」という作品ですが、rotten tomatoでは「THE TRUE MEMOIRS OF AN INTERNATIONAL ASSASSIN」と「THE」がついてしまっています。(大文字小文字は全てURLが小文字であり、URLにする際にタイトルを小文字に変えているので問題ないです)
高得点の点数の映画をcsvファイルに出力する
この記事の頭でも書きました以下の手順の「3」のところの実装に移ります。
wikipediaのnetflix original映画一覧をスクレイピングで取得
取得した映画一覧データを元にrotten tomatoesにアクセスして評価の値を取得
取得した評価の値から値の高い映画を求める
点数を取得するところまでできたので後は「ある閾値以上の映画をcsvに出力する」だけです。
上記プログラムに対して、以下のようにコードを追記します。
from rotten_tomatoes_scraper.rt_scraper import MovieScraper
import pandas as pd
import requests
from urllib.error import HTTPError
import re
import time
url_20152017 = "https://en.wikipedia.org/wiki/List_of_Netflix_original_films_(2015%E2%80%932017)"
df_20152017 = pd.read_html(url_20152017)
dict_20152017 = df_20152017[0].to_dict()
base_tomato_url = "https://www.rottentomatoes.com/m/"
high_score_rotten_point_list = []
high_score_rotten_name_list = []
high_score_audience_point_list = []
high_score_audience_name_list = []
both_high_rotten_audience_rotten_point_list = []
both_high_rotten_audience_audience_point_list = []
both_high_rotten_audience_name_list = []
for (title, premiere_day) in zip(dict_20152017['Title'].values(), dict_20152017['Premiere'].values()):
original_title = title.replace(' ', '_')
original_title = original_title.replace("'", '')
original_title = original_title.replace("-", '_')
original_title = original_title.lower()
year = re.findall('\S\d\d\d', premiere_day)
title_with_year = original_title + "_" + year[0]
time.sleep(3)
try:
movie_url = base_tomato_url + original_title
movie_scraper = MovieScraper(movie_url=movie_url)
movie_scraper.extract_metadata()
#### 👇👇👇ここから追加👇👇👇 ####
if movie_scraper.metadata["Score_Rotten"] is not '':
if int(movie_scraper.metadata["Score_Rotten"]) >= 80:
high_score_rotten_name_list.append(original_title)
high_score_rotten_point_list.append(movie_scraper.metadata["Score_Rotten"])
if movie_scraper.metadata["Score_Audience"] is not '':
if int(movie_scraper.metadata["Score_Audience"]) >= 75:
high_score_audience_name_list.append(original_title)
high_score_audience_point_list.append(movie_scraper.metadata["Score_Audience"])
if (movie_scraper.metadata["Score_Rotten"] is not '') and (movie_scraper.metadata["Score_Audience"] is not ''):
if ( int(movie_scraper.metadata["Score_Rotten"]) >= 80 ) and ( int(movie_scraper.metadata["Score_Audience"]) >= 75 ):
both_high_rotten_audience_name_list.append(original_title)
both_high_rotten_audience_rotten_point_list.append(movie_scraper.metadata["Score_Rotten"])
both_high_rotten_audience_audience_point_list.append(movie_scraper.metadata["Score_Audience"])
#### 👆👆👆ここまで追加👆👆👆 ####
except UnicodeEncodeError:
print("unicode error")
except HTTPError:
try:
movie_url = base_tomato_url + title_with_year
movie_scraper = MovieScraper(movie_url=movie_url)
movie_scraper.extract_metadata()
#### 👇👇👇ここから追加👇👇👇 ####
if movie_scraper.metadata["Score_Rotten"] is not '':
if int(movie_scraper.metadata["Score_Rotten"]) >= 80:
high_score_rotten_name_list.append(original_title)
high_score_rotten_point_list.append(movie_scraper.metadata["Score_Rotten"])
if movie_scraper.metadata["Score_Audience"] is not '':
if int(movie_scraper.metadata["Score_Audience"]) >= 75:
high_score_audience_name_list.append(original_title)
high_score_audience_point_list.append(movie_scraper.metadata["Score_Audience"])
if (movie_scraper.metadata["Score_Rotten"] is not '') and (movie_scraper.metadata["Score_Audience"] is not ''):
if ( int(movie_scraper.metadata["Score_Rotten"]) >= 80 ) and ( int(movie_scraper.metadata["Score_Audience"]) >= 75 ):
both_high_rotten_audience_name_list.append(original_title)
both_high_rotten_audience_rotten_point_list.append(movie_scraper.metadata["Score_Rotten"])
both_high_rotten_audience_audience_point_list.append(movie_scraper.metadata["Score_Audience"])
#### 👆👆👆ここまで追加👆👆👆 ####
except:
pass
#### 👇👇👇ここから追加👇👇👇 ####
dict_both_high_point = {'name': both_high_rotten_audience_name_list, \
'rotten point': both_high_rotten_audience_rotten_point_list, \
'audience point': both_high_rotten_audience_audience_point_list}
df_both_high_point = pd.DataFrame(dict_both_high_point)
df_both_high_point.to_csv('both_high_point.csv')
#### 👆👆👆ここまで追加👆👆👆 ####


 www.rottentomatoes.com
www.rottentomatoes.com

 www.rottentomatoes.com
www.rottentomatoes.com

 www.rottentomatoes.com
www.rottentomatoes.com
 www.rottentomatoes.com
www.rottentomatoes.com
 www.rottentomatoes.com
www.rottentomatoes.com

 www.rottentomatoes.com
www.rottentomatoes.com
 www.rottentomatoes.com
www.rottentomatoes.com
 www.rottentomatoes.com
www.rottentomatoes.com
 www.rottentomatoes.com
www.rottentomatoes.com

 www.rottentomatoes.com
www.rottentomatoes.com
 www.rottentomatoes.com
www.rottentomatoes.com

 www.rottentomatoes.com
www.rottentomatoes.com
 www.rottentomatoes.com
www.rottentomatoes.com

 www.rottentomatoes.com
www.rottentomatoes.com

 www.rottentomatoes.com
・・・【略】・・・
www.rottentomatoes.com
・・・【略】・・・

