
はじめに
前回は食べログの項目に関して可視化を行いました。
前回も記載しましたが評価値については食べログのページに「その時点でユーザーからの評価がどのくらい集まっているのかという見方を示す指標で、お店や料理について絶対的・確定的な優劣を示すものではありません。」と記載してあり、私も衝撃を受けました。
しかし、私はあきらめていませんでした。
可視化した際にも評価値が高くなりがちな項目が幾つかあったので、それらを変数にして回帰をすればなんかしら指標を決定づける要因がわかるんじゃないかって。
てことで、今回は回帰分析をやっていきたいと思います。
ランダムフォレストを使って。
使用するデータは東京にあるレストラン、約14万件。(前回と一緒)
ランダムフォレストによる回帰
suumoの家賃をランダムフォレストを使って分析した際と同様のコードを書いていきます。
suumoの家賃をランダムフォレストで分析した記事はこちら
今回はランチとディナーで分けてみました。
理由としてはディナーだけのお店もあったりするからです。
ランチ
説明変数は以下です。
受賞アワードの数、東京のエリア(区や市)、ランチの価格帯、アワード、ジャンル、「空間・設備」、「利用シーン」、「飲み物」、「食べ物」
回帰の際のコードは以下のような感じで、(参考程度にしてください)
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
import numpy as np
from sklearn.ensemble import RandomForestRegressor
frf = RandomForestRegressor()
X_train, X_test, y_train, y_test = train_test_split(lunch_train_data, y_data, test_size=0.2, random_state=1, shuffle=True)
frf.fit(X_train, y_train)
y_pred_train = frf.predict(X_train)
rsme_train = np.sqrt(MSE(y_train, y_pred_train))
print(rsme_train)
y_pred_test = frf.predict(X_test)
rsme_test = np.sqrt(MSE(y_test, y_pred_test))
print(rsme_test)実行結果は以下です。
0.05543106695342894 0.12260458899754725
学習データに対する回帰への評価(RMSEの値)は0.05なので割と良くできているようには見えますが、
テストデータの評価(RMSEの値)は0.1ほどです。
食べログの評価値が5段階評価なので0.1ほどであればよさげには見えますが、
学習データの結果(RMSE値の値)と比べると過学習しているようにも見えます。
過学習気味なのでグリッドサーチをしようとしましたが、鬼のように時間がかかってしまい、終わらないため断念しました。
テストデータの実際の評価値とテストデータの予測値をプロットしてみます。
つまり上記コードのy_testとy_pred_testをプロットするとどうなるかというと以下のようになります。
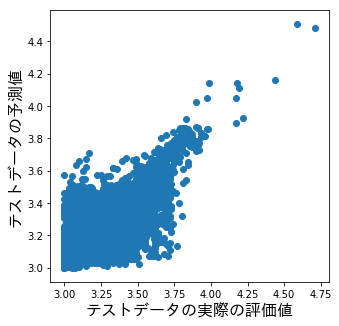
評価値が3.6より下あたりの予測が結構ブレていますね。
重要度
続いて重要度も記載しておきます。
受賞アワードの数 : 0.16249697611484515 ランチの価格帯 : 0.039767235094965395 デート(利用シーン) : 0.009362529554135498 家族・子供と(利用シーン) : 0.00927206372323509 オシャレな空間(空間・設備) : 0.00924186925183577 東京のエリア_新宿区 : 0.009133278772834033 東京のエリア_中央区 : 0.008801078866482622 東京のエリア_渋谷区 : 0.008381953054792179 東京のエリア_千代田区 : 0.008256835670418386 東京のエリア_世田谷区 : 0.007695653484133357 東京のエリア_港区 : 0.00715940678240202 東京のエリア_台東区 : 0.0068204066382093875 東京のエリア_目黒区 : 0.00619901447907379 日本酒あり(飲み物) : 0.0054901393473163335 野菜料理にこだわる(食べ物) : 0.0049418729309942035 カクテルあり(飲み物) : 0.004720594215755031 東京のエリア_豊島区 : 0.004338298693177134 焼酎あり(飲み物) : 0.004298162593644763 東京のエリア_練馬区 : 0.0038314825064096427 東京のエリア_品川区 : 0.0037966695706905416
ディナー
ディナーもランチと同様に見ていきます。
コードはランチの時と一緒ですので割愛します。
ランチの時と違うのは、説明変数が、ランチの金額でなく、ディナーの金額になっているところです。
結果としては以下です。
0.030806462720824455 👈学習データへの回帰に対するRMSE 0.07721604145259992 👈テストデータへの回帰に対するRMSE
こちらも一旦グリッドサーチは時間がかかるので断念。
ディナーの方もテストデータの実際の評価値とテストデータの予測値をプロットしてみます。

こちらもランチと同様に評価値が3.6より下あたりの予測が結構ブレていますね。
重要度
続いて重要度。
受賞アワードの数 : 0.17635770524719518 ディナーの価格帯 : 0.08151763153166824 東京のエリア_新宿区 : 0.010565486917498606 オシャレな空間(空間・設備) : 0.010427621852225833 東京のエリア_渋谷区 : 0.008527283892203918 東京のエリア_中央区 : 0.008335894338795835 カクテルあり(飲み物) : 0.007974891323699797 東京のエリア_千代田区 : 0.007970769866860065 東京のエリア_港区 : 0.00764077531561696 デート(利用シーン) : 0.007312339205030982 東京のエリア_世田谷区 : 0.007268455874483888 家族・子供と(利用シーン) : 0.007262653126841488 東京のエリア_台東区 : 0.006728605470091045 東京のエリア_目黒区 : 0.0065003396953121325 野菜料理にこだわる(料理) : 0.005319561436981211 日本酒あり(飲み物) : 0.005244951490716626 東京のエリア_豊島区 : 0.004807170582536193 居酒屋(ジャンル) : 0.004025021292179151 焼酎あり(飲み物) : 0.003808877196627767 ワインあり(飲み物) : 0.003611337597088606
まとめ
まとめです。
今回は食べログの東京のレストランデータ14万件を基にランダムフォレストで回帰分析を行いました。
精度としてはあまりいいものではない結果に終わりました。
また評価値を決定づける説明変数の重要度をもとめたところ、「受賞アワードの数」が大きく影響していました。
やはり、この評価値は絶対的・確定的な優劣を示すものではないのかもしれないですね。
絶対的・確定的な優劣を示すものではないのかもしれないということを証明できましたね(笑)
今回はここまで。ではまた。👋👋👋
