
我々はpythonでPDFから表を取得できるという情報聞きつけ、現場に急行した。
ジャングルの奥地、そこに住む原住民族は「tabula」というツールを使っていた。。

はい、茶番はここまでとしてpythonを使ってPDFファイルの表をデータとして取得できるようです。
「tabula」というものを使うらしいです。
まずは使ってみるのが一番理解が深まるので使ってみます。
🤩この記事のゴール
PDFを入力したらバランスシートの画像を作成してくれるpythonプログラムを作成する。
完成イメージは以下です。👇
tablulaを使ってみる💻
今回はトヨタの決算短信PDF資料を使ってみます。こちらですね。
今回のコードを書く環境としてはwindows10のjupyter notebookで書きました。
早速、pythonでコードを書いていきます。
とその前にtabulaをインストールしないといけませんね。
今回はjupyter notebookを使用しているのでanaconda promptを開いて、以下のコマンドでインストールを行います。
conda install -c conda-forge tabula-pyデータの構成は以下のようになっています。
|
┣-- 2021_7203.pdf
┗-- PDF_reader.ipynb 👈今回のプログラムで、プログラムは以下のようになっています。
import tabula
pdf_path = './2021_7203.pdf'
dfs = tabula.read_pdf(pdf_path, stream=True, pages="all", multiple_tables=True)
print(len(dfs))はい、これだけです。
「おいおい、嘘つくなよ」って思うかもしれませんが、マジです。
このdfsにリストでpdfのいくつもの表が入っています。
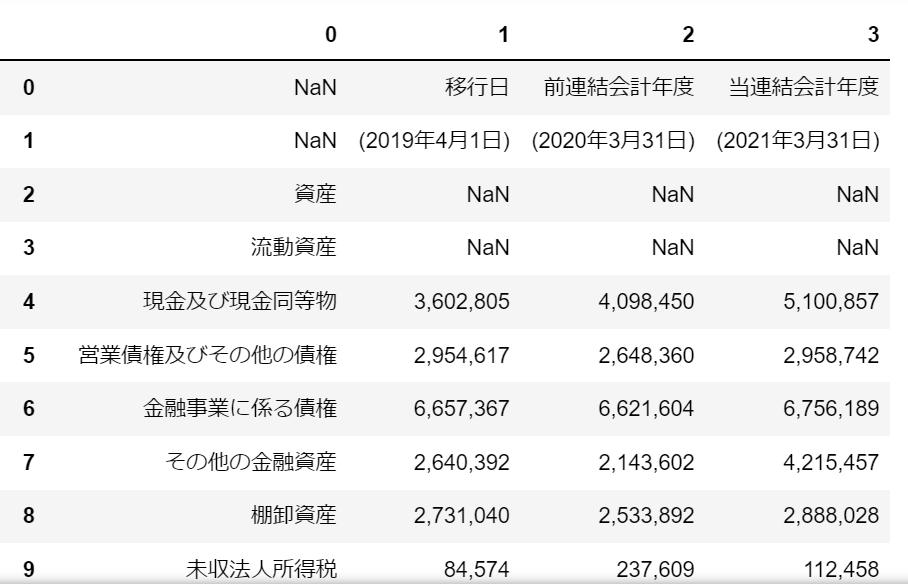
試しに貸借対照表を見てみましょう。
貸借貸借表はdfs[11]に入っていました。
dfs[11]実行すると以下のような表が表示されます。(一部です)
実際のpdfは以下のようになっています👇
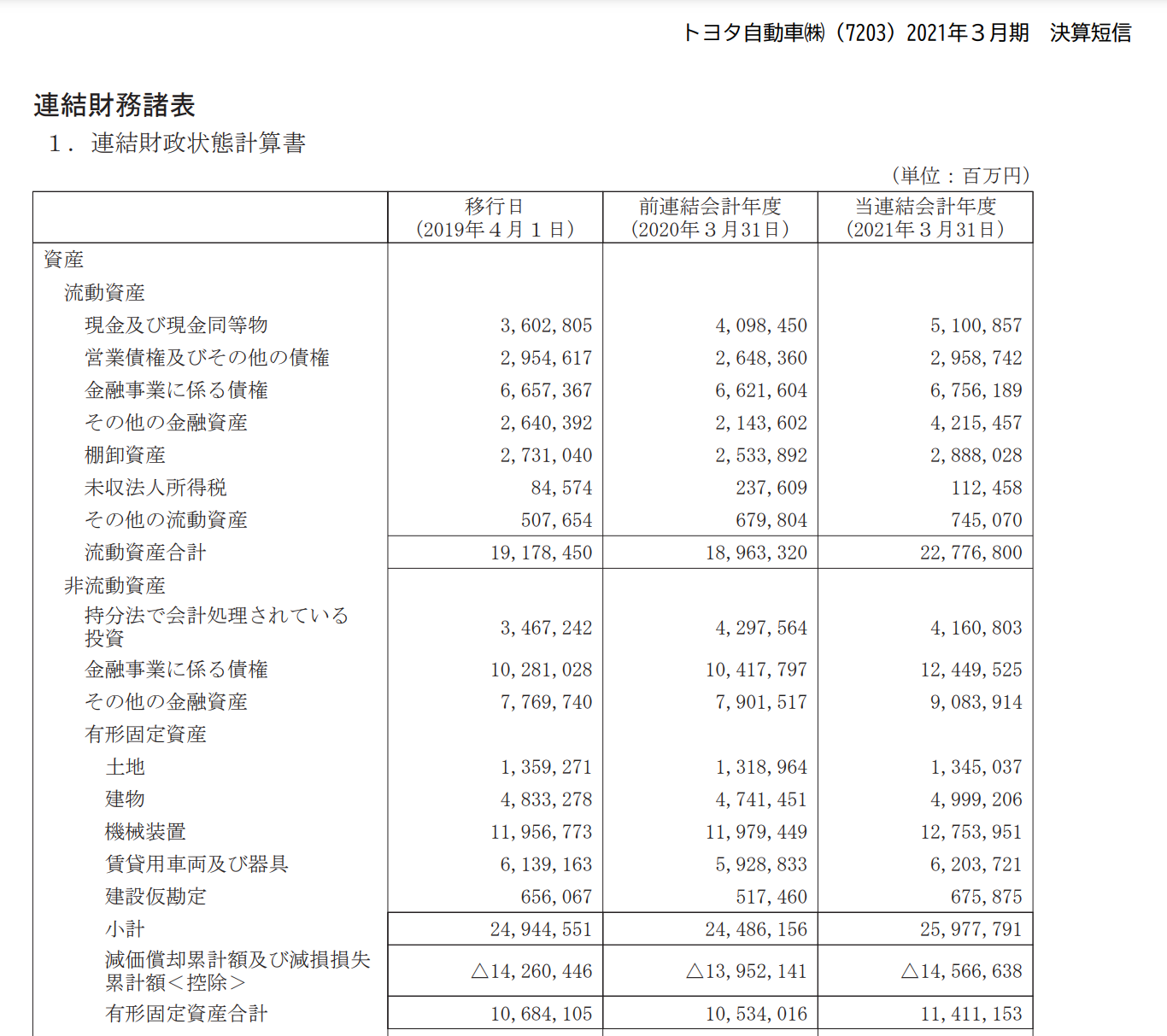
pythonで出力した表と実際のPDFの貸借対照表を比べると以下の2つの事が分かります。
ここまででPDFの表が取得できました。
値を取得する📜
続いて値を取得していきます。
ここで問題となるのが、どの表が貸借対照表なのかをプログラムにわからせなければならないことです。
ですのでまずは目的の貸借対照表の特徴を見ていきます。
すると、資産の後に流動資産がくることが特徴としてわかるかと思います。
他の表で資産の次に流動資産がくる表は無いのでここに着目してプログラムを書いていきたいと思います。
という事で書いたプログラムが以下です👇
import pandas as pd
for df in dfs:
try:
## 対象DFが貸借対照表かを確認
if df.at[df.index[2], df.columns[0]] == "資産" and df.at[df.index[3], df.columns[0]] == "流動資産":
for index, row in df.iterrows():
## 一行ずつみていき0行目の値を見ていく
if row[0] == "資産合計":
sisan_goukei = int(row[3].replace(',', ''))
print(sisan_goukei)
break
if df.at[df.index[2], df.columns[0]] == "負債" and df.at[df.index[3], df.columns[0]] == "流動負債":
for index, row in df.iterrows():
## 一行ずつみていき0行目の値を見ていく
if row[0] == "負債合計":
fusai_goukei = int(row[3].replace(',', ''))
print(fusai_goukei)
#break
if row[0] == "資本合計":
shihon_goukei = int(row[3].replace(',', ''))
print(shihon_goukei)
break
except:
pass
############ 出力結果 #############
## 62267140
## 37978811
## 24288329まず4行目、26行目のtry-exceptですが、これはindex[2]などが後に出てくるのですが、この際、表によってはindex[2]が無いものがあるのでエラーになってしまいます。それを防ぐためにこの処理を行っています。
そして6行目が上記で説明した「資産の後に流動資産がくる」表であるかを確認しています。
これが確認できてOKならif文の中に入って処理を行っていきます。
7行目では表を一行ずつ見ていくためにfor文を回しています。
そして項目として資産合計が見つかれば、その時の行の値を資産合計の値として取得します。
取得に際しては、値に「,」が含まれていることと、値が文字列である事から「int(row[3].replace(‘,’, ”))」というように「,」を省いて、文字列ではなく整数型(int型)に変えてあります。
同様の処理を14~25行で今度は負債と純資産(資本)に対して行っています。
バランスシートを描画する🎨
次はついに描画ですね。
描画にはplotlyを使用します。
まずはjupyter notebookにはデフォルトでplotlyが入っていないのでインストールする必要があります。
いつものようにanaconda promptを開いて以下コマンドでインストールしてみて下さい。
conda install -c plotly plotlyそして以下のようにプログラムを書きます。
from plotly import graph_objects as go
data = {
"Asset":[sisan_goukei],
"Liabilities":[fusai_goukei],
"Net Asset":[shihon_goukei]
}
fig1 = go.Figure(
data=[
go.Bar(
name="資産",
y=data["Asset"],
text=data["Asset"],
offsetgroup=0,
marker_color='#87ceeb',
),
go.Bar(
name="負債",
y=data["Liabilities"],
text=data["Liabilities"],
offsetgroup=1,
base=data["Net Asset"],
marker_color='#fa8072',
),
go.Bar(
name="純資産",
y=data["Net Asset"],
text=data["Net Asset"],
offsetgroup=1,
marker_color='#9acd32',
),
]
)
fig1.show()で実行すると以下のような感じで図が出力されるかと思います。
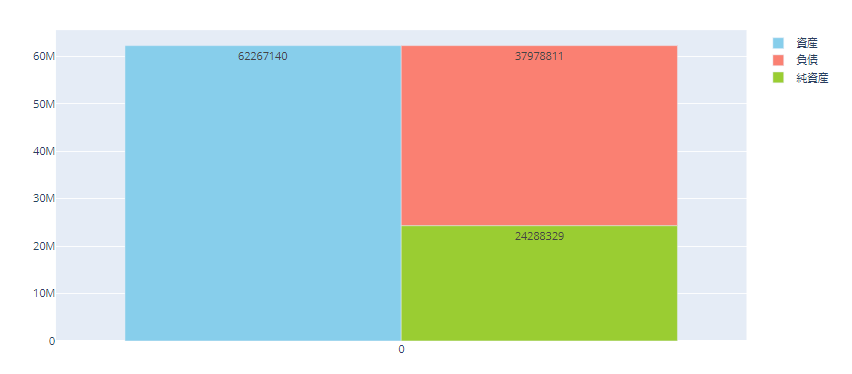
はい!これで貸借対照表ができました!!
補足:当初matplotlibで動かそうとしてうまくいかず悶絶しました
matplotlibで最初作成しようと思っていました。以下のようなプログラムを書くと
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
sns.set(font='IPAexGothic')
%matplotlib inline
x = ["Asset", "Liabilities,Equity"]
height = [sisan_goukei, shihon_goukei]
height2 = [0, fusai_goukei]
plt.bar(x, height)
plt.bar(x, height2, bottom=height)
plt.show()以下のような図が出力されます。
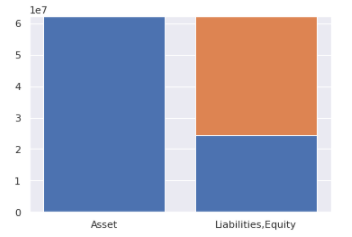
でも色が資産と純資産のところ同じになって違う色にできないんですね。。
調べましたができないよう。。。
あ”あ”あ”あ”ってなってしまったのでplotlyを使用してみました。
😎まとめ
はい、今回はPDFを入力にしたら貸借対照表を出力できるプログラムを作成しました。
これ、資産、負債、純資産で出力をしましたが、流動資産とか細かく分けて出力もできます。
そして貸借対照表だけでなく損益計算書やキャッシュフロー計算書の作成をするという応用もできるかと思います。
後は皆さんの思うがままPDF可視化ライフをエンジョイしてみてください。
今回はここまで。最後まで読んでいただきありがとうございました。
