
pythonではまったところの備忘録のための記事です。
自分の備忘録と同時に共有をしてはまる時間を少なくするためのものになります。
今回の事例が発生した環境はwindows10でjupyter notebookを使っています。なのでpython3を使っています。
正規表現のパイプ(|)の扱いについて(jupyter notebook)
はまった事例 (20201105記)
例えばデータを扱う時以下のような値があったとします。1つめは「this value is 2B dollar」2つめは「this value is 50M dollar」。これはアメリカの金額の数値を表すデータになります。BはBillion(10億)なので2Bは20億ドルで2B=2×1000000000を表し、MはMinion(100万)なので50は5000万ドルで50M=50×1000000を表します。
そして、この値を「this value is 2B dollar」「this value is 500M dollar」から数値だけ取り出したいとします(この例の場合2Bと500Mを取り出します)。数値だけ取り出して計算に用いる必要があるときなどが考えられます。
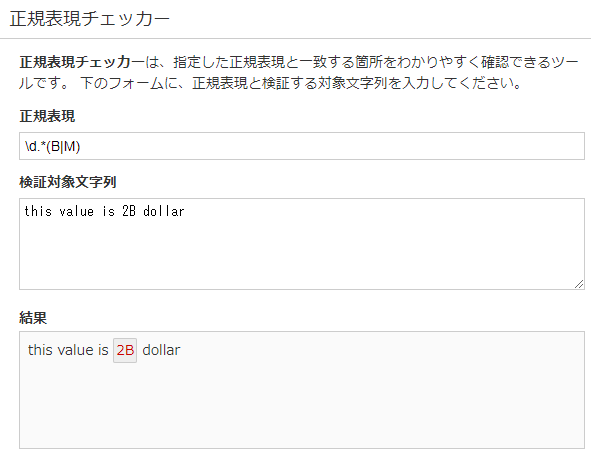
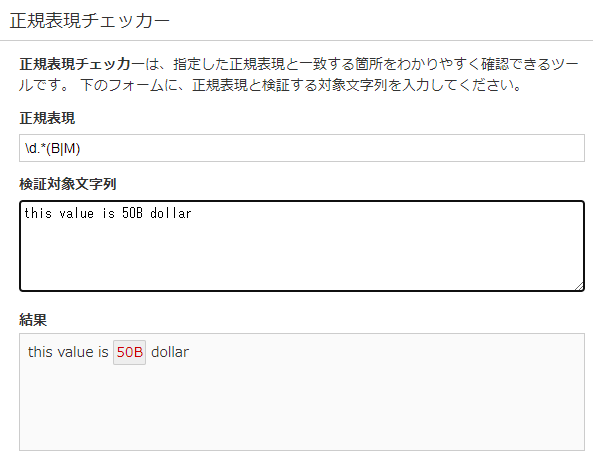
この時、正規表現を「\d.*(B|M)」のようにして数値(\d)から始まってBまたM(B|M)で終わる文字列(xから始まってyで終わる文字列はx.*yで表現される)としたときになぜかMとBしか抽出できません。
つまり以下のような感じ
import re
text_1 = "this value is 2B dollar"
text_2 = "this value is 50M dollar"
num_1 = re.findall('\d.*(B|M)', text_1)
num_2 = re.findall('\d.*(B|M)', text_2)
print(num_1)
print(num_2)
#出力は以下
#['B']
#['M']正規表現チェッカーで確認しても、問題なく2Bと50Mはとりだせます。正規表現チェッカーのリンクは以下です。正規表現を試したいときは使ってみてください

正規表現チェッカー | WEB ARCH LABO
正規表現チェッカーは、指定した正規表現がどのようにマッチするのかを検証・可視化するための開発補助ツールです。
weblabo.oscasierra.net
どうやって解決したか
どうやら「\d.*B|\d.*M」のようにパイプを使わないといけないっぽい。これで書くと以下のようにうまく抽出できる。
import re
text_1 = "this value is 2B dollar"
text_2 = "this value is 50M dollar"
num_1 = re.findall('\d.*B|\d.*M', text_1)
num_2 = re.findall('\d.*B|\d.*M', text_2)
print(num_1)
print(num_2)
#出力は以下
#['2B']
#['50M']
