
あらすじ
前回は残差分析を行い、その結果を基に精度を少しだけ改善することができました。
少しだけ。
(以前も別の記事で載せましたが)食べログ公式が食べログの評価値についてこんなことを書いています。
その時点でユーザーからの評価がどのくらい集まっているのかという見方を示す指標で、お店や料理について絶対的・確定的な優劣を示すものではありません。」
で、ふと思いついたのですが、ユーザーのコメント数やブックマークの数が多ければそのお店に注目が集まっているわけで、必然的に評価も集まるかと思います。
よってユーザーのコメント数やブックマークの数によって評価値をより高い精度で予測できるのではないかと思いました。
今回の記事は…
ということで、今回の記事でまとめることは以下の2つを含めて再度ランダムフォレストを実行して見ます。
- 口コミ数
- ブックマーク数
そして、タイトルにもあるように、今回は東京ではなく北海道のお店のデータを使います。
東京のデータは集めるのに3週間ほどかかるからです…。
(北海道でも5日ぐらいかかりましたが…。)
ざっくり結論
先にざっくりとした結論から。
今回の試みは成功です。😊
この記事ではどれくらい精度が上がったかを知ることができます。
ランダムフォレスト(ランチ)🍛
まずはランチの評価値についてランダムフォレストで回帰を行っていきます。
前回までの場合
前回までは口コミ数とブックマーク数は入れていなかったです。
それらを入れなかった場合の結果は以下のようになります。
学習データに対する回帰への評価(RMSEの値):0.06577853276638693 学習データに対する決定係数:0.42313109233032353 テストデータに対する回帰への評価(RMSEの値):0.1128489154867508 テストデータに対する決定係数:0.4819613303551538
テストデータの実際の評価値とテストデータの予測値をプロットした結果は以下です。
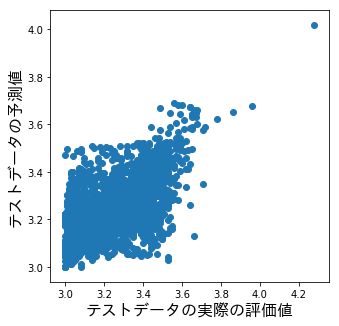
誤った予測が多いですね。
今回のパラメータを追加した場合
口コミ数とブックマーク数は入れた結果は以下です。
学習データに対する回帰への評価(RMSEの値):0.024356258290136996 学習データに対する決定係数:0.973496495723662 テストデータに対する回帰への評価(RMSEの値):0.058938612465008 テストデータに対する決定係数:0.8482439650622495
口コミ数とブックマーク数は入れなかった場合に比べて精度が上がりましたね。
ただし、学習データの決定係数に比べて、テストデータの決定係数が下がっているので、少し過学習気味に見えます。
テストデータの実際の評価値とテストデータの予測値をプロットした結果は以下です。
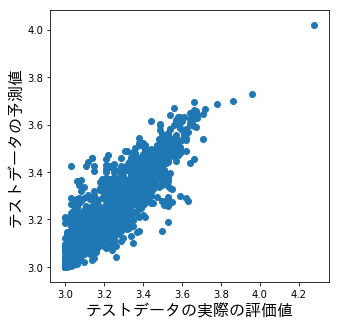
重要度
重要度のベスト10は以下。
ブックマーク数 : 0.6210372033431895 レビューコメント数 : 0.1685255884027994 ランチの価格帯 : 0.01042459426094446 受賞アワード数 : 0.008557087072625508 利用シーン(家族・子供と) : 0.002987705151313196 空間・設備(オシャレな空間) : 0.002225469992214736 空間・設備(景色がきれい) : 0.0017197122895780271 ドリンク(日本酒あり) : 0.0016071414074297799 ドリンク(焼酎あり) : 0.001459818967504428 空間・設備(落ち着いた空間) : 0.001227514186389065
ブックマーク数とレビューコメント数がほとんど影響している事が分かります。
それ以外はほとんど影響していません。
ランダムフォレスト(ディナー)🍷
続いて、ディナーのランダムフォレストによる回帰を行っていきます。
前回までの場合
ディナーの口コミ数とブックマーク数は入れていなかった場合の結果は以下です。
学習データに対する回帰への評価(RMSEの値):0.06815149806467392 学習データに対する決定係数:0.8434869276478605 テストデータに対する回帰への評価(RMSEの値):0.12854883101880826 テストデータに対する決定係数:0.42578260709872723
学習データに決定係数に対して、テストデータの決定係数がガッツリ下がっていますね。
ガッツリ過学習しています。
テストデータの実際の評価値とテストデータの予測値をプロットした結果は以下。
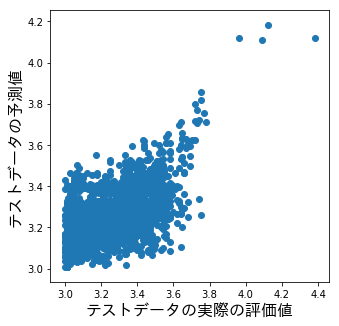
今回のパラメータを追加した場合
口コミ数とブックマーク数は入れた結果は以下です。
学習データに対する回帰への評価(RMSEの値):0.029290585943501805 学習データに対する決定係数:0.9710894787075477 テストデータに対する回帰への評価(RMSEの値):0.06286354101604058 テストデータに対する決定係数:0.8626787459488983
ランチの時と同様に精度が上がっていますね。(ちょっと過学習気味ですが)
テストデータの実際の評価値とテストデータの予測値をプロットした結果は以下。
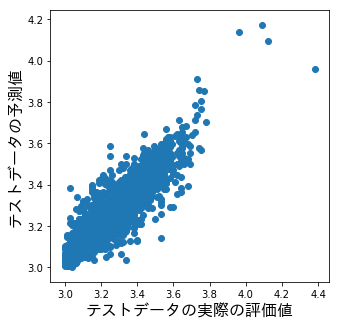
重要度
重要度は以下のような結果になりました。
ブックマーク数 : 0.6252002112748068
レビューコメント数 : 0.14427894582682396
ディナーの価格帯 : 0.023971420453316516
受賞アワード数 : 0.02384045074548622
The Tabelog Award 2023 Bronze 受賞店 : 0.0025767633122838586
利用シーン(家族・子供と) : 0.0023168480407864587
ドリンク(カクテルあり) : 0.0020525861286754604
ドリンク(焼酎あり) : 0.0016964073551823098
ドリンク(ワインあり) : 0.0016924554622878257
空間・設備(オシャレな空間) : 0.0015866747877116057
こちらもランチの時と同様にブックマーク数とレビューコメント数が大きく影響しています。
まとめ
今回は北海道の食べログデータを用いて、評価値予測の改善を試してみました。
結果としては、精度を上げることに成功しました。
いやー、結構嬉しいです。
パラメータだけで評価値の予測はできないと半分諦めていました。
たしかにとてつもなく精度が高いわけではありません。
でも、予測ができないと思っていたところからここまで一気に精度が上がったのは結構な前進だと思います。
というかこれ以上精度上げることはできそうもありません。
次回以降、もう少しだけ深堀してみようと思います。
今回はここまで。ではまた👋👋👋
その他、レストラン予約の広告

