
※今回の分析は2022年7月に集めたデータでしています。
全国分データを集める
前回までで札幌のお店の情報まで集めた。
今回は北海道全体のお店の情報を集め、最終的には全国のお店の情報を集める。
以下のような流れで。
①札幌駅周辺のお店の情報をできるだけすべて集め、
②その次に札幌のお店の情報をできるだけすべて集め、(←★前回はここまで)
③最後には北海道全土のお店の情報をできるだけすべて集めます。(←★今回はここから)
というところなんだけど、いっそのこともう全国のデータを集めるようにしたコードから載せちゃうね。
もう結果からね、載せちゃうね。
前回の最後の記事のコードあるよね。「ステップ②のコード」のところのコード
これに以下を追加して完成!
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
todoufuken_list = [
"hokkaido/A01",
"aomori/A02", "iwate/A03", "miyagi/A04", "akita/A05", "yamagata/A06", "fukushima/A07",
"ibaraki/A08", "tochigi/A09", "gunma/A10", "saitama/A11", "chiba/A12", "tokyo/A13", "kanagawa/A14",
"niigata/A15", "toyama/A16", "ishikawa/A17", "fukui/A18", "yamanashi/A19", "nagano/A20",
"gifu/A21", "shizuoka/A22", "aichi/A23", "mie/A24",
"shiga/A25", "kyoto/A26", "osaka/A27", "hyogo/A28", "nara/A29", "wakayama/A30",
"tottori/A31", "shimane/A32", "okayama/A33", "hiroshima/A34", "yamaguchi/A35",
"tokushima/A36", "kagawa/A37", "ehime/A38", "kochi/A39",
"fukuoka/A40", "saga/A41", "nagasaki/A42", "kumamoto/A43", "oita/A44", "miyazaki/A45", "kagoshima/A46",
"okinawa/A47"
]
for todoufuken_item in todoufuken_list: # 全国分のループ
count = 0
for todoufuken_erea_num in range(1, 15): # エリア別 このループで都道府県の一つ分 A0101とか、A0102とか
info_dict = {}
url_elem = todoufuken_item.split('/')
if todoufuken_erea_num < 10:
place_num = url_elem[1] + "0" + str(todoufuken_erea_num)
elif todoufuken_erea_num >= 10:
place_num = url_elem[1] + str(todoufuken_erea_num)
## ここまででA0101, A0102ができる
#============================================
# 🤗前回の「ステップ②のコード」のところのコード(importのところは抜いてね! あと追加したfor文に合わせてインデント)
'''
for erea_num in range(1, 30):
if erea_num < 10:
erea_item = url_elem[1] + "0" + str(erea_num)
elif erea_num >= 10:
erea_item = url_elem[1] + str(erea_num)
### ・・・略・・・
'''
#============================================
output_df = pd.DataFrame(info_dict)
output_df.to_csv('【csvファイルを出力するpath】/erea_data_' + place_num + "_" + url_elem[0] + '.csv', encoding='utf_8_sig')ちなみに以下の部分について、1~14でfor文が回ることになるんだけど、東京のエリア数が凄い多いので14じゃ納まらない。だから別途rangeを変えて東京だけ集める必要がある。
for todoufuken_erea_num in range(1, 15): # エリア別 このループで都道府県の一つ分 A0101とか、A0102とかそして集めるんだけど、前回まではjupyter notebookでパソコンでプログラムを実行してた。
だけど北海道の札幌だけでも相当時間がかかったからラズベリーパイで動かすことにした。
バックグラウンド実行をして、プログラムを実行させて放置することにした。
ほぼ5日かかったよ。。
バックグラウンド実行はこちらの記事なんかを読むのがおススメかな。
このプログラムでエリアごとのデータがまとめて1つのcsvファイルとして出力される。
上記コードの以下の部分で。
output_df.to_csv('【csvファイルを出力するpath】/erea_data_' + place_num + "_" + url_elem[0] + '.csv', encoding='utf_8_sig')データを見てみる
集めたcsvデータをpythonのdataframeとして読み込んで分析をする。
試しに北海道から。
まずはエリアごとにcsv出力されているからこれらをつなげて一つのdataframeとして作る必要がある。
レシピとしては
- Pandasのread_csvを使ってdataframeを作る
- エリアごとに分かれているからconcatを使ってhokkaidoのdataframeを結合させて1つのdataframeを作る
- 転置させる(transpose()を使う)
下の方に行数が出てるけど、35225件ある。
北海道だけで3万件以上のデータがあるということで、全部ですごい量になりそう。
まずは一旦、昼の値段と夜の値段の値がどんな値があるかを見てみる。
昼の値段はday_value、夜の値段はnight_valueなので以下のようにvalue_countsを使用して見てみる。
print(df_hokkaido_tr['day_value'].value_counts())
print("--------------------------------------")
print(df_hokkaido_tr['night_value'].value_counts())実行結果は以下。
~¥999 16817
- 8774
¥1,000~¥1,999 7517
¥2,000~¥2,999 937
¥3,000~¥3,999 366
¥6,000~¥7,999 222
¥5,000~¥5,999 174
¥4,000~¥4,999 169
¥10,000~¥14,999 101
¥8,000~¥9,999 70
¥20,000~¥29,999 29
¥15,000~¥19,999 26
¥30,000~¥39,999 11
¥40,000~¥49,999 9
¥50,000~¥59,999 2
¥100,000~ 1
Name: night_value, dtype: int64
--------------------------------------
- 16917
~¥999 4813
¥1,000~¥1,999 3739
¥2,000~¥2,999 2864
¥3,000~¥3,999 2682
¥4,000~¥4,999 1451
¥5,000~¥5,999 815
¥6,000~¥7,999 664
¥10,000~¥14,999 520
¥8,000~¥9,999 423
¥15,000~¥19,999 163
¥20,000~¥29,999 114
¥30,000~¥39,999 37
¥40,000~¥49,999 10
¥60,000~¥79,999 6
¥80,000~¥99,999 5
¥100,000~ 2
Name: day_value, dtype: int64各値は18種類の値段範囲がある事がわかる。
「-」を除いた17種類の値が、各お店の評価とどのような関係があるのかを見ていく。
ラベルをそれぞれの価格帯に貼る。
「~¥999」なら「1」、「¥1,000~¥1,999」なら「2」…という具合だ。
そしてラベルの値を横軸に、評価値を縦軸にとった散布図を出力する。
ラベルが大きくなれば値段が大きくなる。つまり、ラベルが大きくなっていくに従って評価値も上がるのであれば値段によってある程度評価値も決まっているという事になる。
要は値段と評価値の相関を調べようという訳である。
ちなみに今回は値段が無いもの、「-」の価格帯の評価値のものは考えていない。
お昼(ランチ)の値段の散布図
まずはお昼(ランチ)の値段と評価値から。横軸がラベルの値、縦軸が評価値
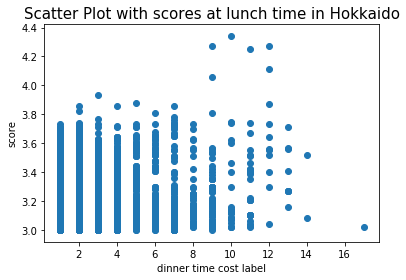
もうグラフから相関が無いのはわかるね。。。🥲
2つの変数の関係がどれだけ強いのか、又は弱いのかを相関係数という数値で表すんだけど、今回の相関係数は「0.09281」。
相関係数は「1」に近ければ近いほど相関があるといわれ、だいたい0.7ぐらいあればある程度の相関があるねって言われるから、今回は全然ない事がわかる。
夜(ディナー)の値段の散布図
お次は夜(ディナー)の値段と評価値。お昼(ランチ)の値段の時と同様に横軸がラベルの値、縦軸が評価値
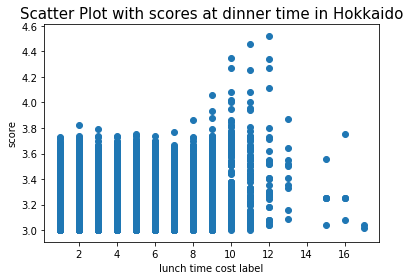
はい、これも相関がない事は分かるね。。。
ちなみに相関係数は「0.05988」。
もう全然ないね。
✅ちょっと余談「こんなエラー出ませんでしたか?」▶「ValueError: scatter requires y column to be numeric」
散布図を表示するときに出たエラー。
僕の場合はdf_hokkaido_trに格納されている評価値(score)の値がおかしかったようで、散布図の入力の値のtypeを確認してみよう!
試しにscoreのtypeを見てみる
for i in df_hokkaido_tr['score']:
print(type(i))と以下のように出力される
<class 'str'> <class 'str'> <class 'str'> <class 'str'> <class 'str'> <class 'str'> <class 'str'> <class 'str'>
csvファイルから読み込んだからか文字列になってしまっていた。
なので型を変換する。
以下のようにすれば解決。
df_hokkaido_tr["score"]=df_hokkaido_tr["score"].astype(float)全国各都道府県の相関係数を見てみる
全国各都道府県のそれぞれの相関係数を見てみる事にする。
相関係数が1に近ければ値段が高いほど評価が高いという、それは、ある意味でコスパの常識が通用することを意味していると言える。
全国各都道府県の相関係数は以下。
| ランチと評価値の相関係数 | ディナーと評価値の相関係数 | |
| 北海道 | 0.093 | 0.06 |
| 青森県 | 0.105 | 0.1 |
| 岩手県 | 0.097 | 0.089 |
| 宮城県 | 0.118 | 0.136 |
| 秋田県 | 0.178 | 0.148 |
| 山形県 | 0.092 | 0.049 |
| 福島県 | 0.085 | -0 |
| 茨城県 | 0.139 | 0.008 |
| 栃木県 | 0.106 | -0.01 |
| 群馬県 | 0.081 | 0.048 |
| 埼玉県 | 0.104 | 0.036 |
| 千葉県 | 0.114 | 0.052 |
| 神奈川県 | 0.163 | 0.109 |
| 東京都 | 0.242 | 0.245 |
| 新潟県 | 0.045 | -0.04 |
| 富山県 | 0.289 | 0.192 |
| 石川県 | 0.342 | 0.23 |
| 福井県 | 0.086 | 0.032 |
| 山梨県 | 0.074 | 0.032 |
| 長野県 | 0.108 | 0.038 |
| 岐阜県 | 0.109 | 0.033 |
| 静岡県 | 0.176 | 0.067 |
| 愛知県 | 0.23 | 0.217 |
| 三重県 | 0.137 | 0.093 |
| 滋賀県 | 0.204 | 0.136 |
| 京都府 | 0.14 | 0.031 |
| 大阪府 | 0.209 | 0.224 |
| 兵庫県 | 0.153 | 0.07 |
| 奈良県 | 0.13 | 0.087 |
| 和歌山県 | 0.132 | 0.048 |
| 鳥取県 | 0.102 | 0.093 |
| 島根県 | 0.141 | 0.116 |
| 岡山県 | 0.135 | 0.106 |
| 広島県 | 0.129 | 0.031 |
| 山口県 | 0.138 | 0.087 |
| 徳島県 | 0.105 | 0.092 |
| 香川県 | 0.028 | 0.113 |
| 愛媛県 | 0.103 | 0.06 |
| 高知県 | 0.115 | 0.024 |
| 福岡県 | 0.17 | 0.187 |
| 佐賀県 | 0.185 | 0.15 |
| 長崎県 | 0.128 | 0.114 |
| 熊本県 | 0.128 | 0.056 |
| 大分県 | 0.161 | 0.085 |
| 宮崎県 | 0.185 | 0.144 |
| 鹿児島県 | 0.191 | 0.099 |
| 沖縄県 | 0.067 | 0.138 |
相関係数が最大となったのはランチは石川県の「0.3424」でディナーは東京都の「0.2450」だった。
上記の表の結果から、全体的に日本のレストランにおいてコスパの常識は通用しないことを意味する。
同時にそれは、コスパの良いレストランが存在することも意味する。
つまり、値段が高ければ評価が高いという常識が通用するようなであれば、コスパの概念は無くなる。
一方で値段が高くても評価が低いものがあればコスパは悪いという概念が生まれ、値段が低くても評価が高ければコスパは良いと言う概念が生まれる。
次回以降は、コスパの良いレストランの条件を探してみる事にする。
今回はここまでにする。
最後まで読んでいただきありがとうございました。

