
主にこの記事に書いてある情報
pythonは漢字のソートができない
pythonってひらがなとかカタカナであればソートできるんですが、漢字はソートできないんですよね。
つまり、あいうえお順にすることができないってことですね。
例えば以下のような名前のエクセルファイルがあって、これをソート(あいうえお順に)したい時ってあると思うんですが、(あんま無いですかね)
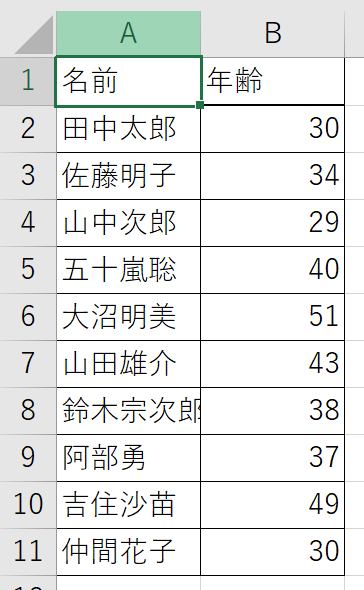
今回は10人の例ですが、これが100人、200人となっていくと大変です。
これ、人の名前だけじゃなくて本などのタイトルのデータなども同様です。
まず、試しに漢字でソートする場合をやってみます。
漢字でソートする場合は以下のようなコードになるかと思います。
import pandas as pd
df_name = pd.read_excel('/path/to/excel/data/名前.xlsx')
new_name_list = sorted(df_name['名前'])
print(new_name_list)この時の出力は以下。
['五十嵐聡', '仲間花子', '佐藤明子', '吉住沙苗', '大沼明美', '山中次郎', '山田雄介', '田中太郎', '鈴木宗次郎', '阿部勇']
あいうえお順になっていませんね。
pythonで漢字のソートをする
では、どうすればよいかと言うと、漢字をひらがなに変換し、ソートします。
何の工夫もありませんね(笑)
ひらがな変換
ソートをする前にひらがな変換をします。
漢字からひらがなへの変換はpykakasiを使います。
$ pip3 install pykakasiimport pandas as pd
import pykakasi
def get_hiragana(x):
kks = pykakasi.kakasi()
return kks.convert(x)[0]['hira']
df_name = pd.read_excel('/path/to/excel/data/名前.xlsx')
df_name['hiragana'] = df_name['名前'].apply(get_hiragana)
print(df_name['hiragana'])出力結果
0 たなか
1 さとう
2 さんちゅう
3 いがらし
4 おおぬま
5 やまだ
6 すずき
7 あべ
8 よしずみ
9 なかま
Name: hiragana, dtype: object2の山中さんが「さんちゅう」になってしまっている以外はあっていますね。
kks.convert(x)[0]['hira']の「kks.convert(x)」の部分で漢字をひらがなに変換しています。
[0][‘hira’]の部分は変換結果に合わせています。kks.convert(x)での変換結果は以下のようになります。
[{'orig': '田中', 'hira': 'たなか', 'kana': 'タナカ', 'hepburn': 'tanaka', 'kunrei': 'tanaka', 'passport': 'tanaka'}, {'orig': '太郎', 'hira': 'たろう', 'kana': 'タロウ', 'hepburn': 'tarou', 'kunrei': 'tarou', 'passport': 'tarou'}]
つまり、ここの[0]番目の[‘hira’]である「たろう」を指定しているということです。
ソート
ひらがな変換した列をソートします。
以下の上記プログラムをハイライトの部分に変更して実行してみます。
import pandas as pd
import pykakasi
def get_hiragana(x):
kks = pykakasi.kakasi()
return kks.convert(x)[0]['hira']
df_name = pd.read_excel('/home/appare99/git_python_codes/python_codes/tests/name_sort/data/名前.xlsx')
df_name['hiragana'] = df_name['名前'].apply(get_hiragana)
df_name = df_name.sort_values(by="hiragana")
print(df_name)実行結果は以下になります。名前、ソートされてますね。
名前 年齢 hiragana
7 阿部勇 37 あべ
3 五十嵐聡 40 いがらし
4 大沼明美 51 おおぬま
1 佐藤明子 34 さとう
2 山中次郎 29 さんちゅう
6 鈴木宗次郎 38 すずき
0 田中太郎 30 たなか
9 仲間花子 30 なかま
5 山田雄介 43 やまだ
8 吉住沙苗 49 よしずみそして、エクセルにこのdataframeを出力させます。
あとは、微修正として「さんちゅう」となっている山中さんを正しいところに移動させてあげます。(移動は手作業です…)
最後は手作業ですが、これである程度のソートはできるので、あとは軽く手作業で修正してあげれば業務としての時間は結構短縮できると思います。

